- Tutorial
Davno, dok sam još bio naivan školarac, odjednom sam postao strašno znatiželjan: kako podaci u arhivama magično zauzimaju manje prostora? Postavivši svoj pouzdani dialup, počeo sam surfati internetom u potrazi za odgovorom i pronašao mnogo članaka s prilično detaljnim prikazom informacija koje su me zanimale. Ali nijedna od njih tada se nije činila lako razumljivom – popisi kodova izgledali su kao kineska pismenost, a pokušaji razumijevanja neobične terminologije i raznih formula nisu bili okrunjeni uspjehom.
Stoga je svrha ovog članka dati ideju o najjednostavnijim algoritmima kompresije onima kojima znanje i iskustvo još ne dopuštaju da odmah razumiju stručnu literaturu, ili čiji je profil potpuno daleko od takvih tema. One. Ispričat ću vam ukratko neke od najjednostavnijih algoritama i dati primjere njihove implementacije bez kilometarskih lista kodova.
Dozvolite mi da vas odmah upozorim da detalje implementacije procesa kodiranja i takve nijanse neću razmatrati kao efikasno traženje pojavljivanja niza. Članak će se baviti samo samim algoritmima i načinima predstavljanja rezultata njihovog rada.
RLE - kompaktnost uniformnosti
RLE algoritam je vjerovatno najjednostavniji od svih: njegova suština leži u kodiranju ponavljanja. Drugim riječima, uzimamo sekvence identični elementi, i "sažmi" ih u parove "količina/vrijednost". Na primjer, niz poput "AAAAAAABCCCC" može se konvertirati u nešto poput "8×A, B, 4×C". Ovo je, općenito, sve što trebate znati o algoritmu.Primjer implementacije
Recimo da imamo skup određenih cjelobrojnih koeficijenata koji mogu imati vrijednosti od 0 do 255. Logično, došli smo do zaključka da je razumno pohraniti ovaj skup kao niz bajtova:unsigned char podaci = ( 0, 0, 0, 0, 0, 0, 4, 2, 0, 4, 4, 4, 4, 4, 4, 4, 80, 80, 80, 80, 0, 2, 2 , 2, 2, 255, 255, 255, 255, 255, 0, 0 );
Za mnoge će biti mnogo uobičajenije da vide ove podatke u obliku heksadecimalne damp:
0000: 00 00 00 00 00 00 04 02 00 04 04 04 04 04 04 04
0010: 50 50 50 50 00 02 02 02 02 FF FF FF FF FF 00 00
Nakon razmišljanja, odlučili smo da bi bilo dobro nekako komprimirati takve setove kako bismo uštedjeli prostor. Da bismo to učinili, analizirali smo ih i identificirali obrazac: vrlo često nailazimo na podsekvence koje se sastoje od identičnih elemenata. Naravno, RLE je savršen za ovo!
Kodirajmo naše podatke koristeći novostečeno znanje: 6x0, 4, 2, 0, 7x4, 4x80, 0, 4x2, 5x255, 2x0.
Vrijeme je da nekako predstavimo naš rezultat u obliku razumljivom kompjuteru. Da bismo to učinili, u toku podataka moramo nekako odvojiti pojedinačne bajtove od kodiranih stringova. Budući da naši podaci koriste cijeli raspon vrijednosti bajtova, neće biti moguće jednostavno odabrati bilo koji raspon vrijednosti za naše potrebe.
Postoje najmanje dva izlaza iz ove situacije:
- Kao indikator komprimovanog lanca, izaberite jednu vrednost bajta, a u slučaju kolizije sa stvarnim podacima, pobegnite od nje. Na primjer, ako koristimo vrijednost 255 za “zvanične” svrhe, onda kada naiđemo na ovu vrijednost u ulaznim podacima bit ćemo prisiljeni napisati “255, 255” i koristiti maksimalno 254 iza indikatora.
- Strukturirajte kodirane podatke, ukazujući na količinu ne samo za ponovljene, već i za naredne pojedinačne elemente. Tada ćemo unaprijed znati gdje su koji podaci.
Dakle, sada imamo dvije vrste nizova: lance pojedinačnih elemenata (poput “4, 2, 0”) i lance identičnih elemenata (poput “0, 0, 0, 0, 0, 0”). Odaberimo jedan bit u bajtovima "servis" za tip sekvence: 0 - pojedinačni elementi, 1 - identični. Za ovo, uzmimo, recimo, najznačajniji bit bajta.
U preostalih 7 bitova ćemo pohraniti dužine sekvenci, tj. maksimalna dužina kodirane sekvence je 127 bajtova. Mogli bismo dodijeliti, recimo, dva bajta za potrebe servisa, ali u našem slučaju tako duge sekvence su izuzetno rijetke, pa ih je lakše i ekonomičnije jednostavno razbiti na kraće.
Ispostavilo se da ćemo prvo zapisati dužinu niza u izlazni tok, a zatim ili jednu ponovljivu vrijednost ili lanac neponovljivih elemenata navedene dužine.
Prva stvar koja bi vam trebala upasti u oči je da u ovoj situaciji imamo nekoliko neiskorištenih vrijednosti. Ne može postojati sekvenca sa nultom dužinom, tako da možemo povećati maksimalnu dužinu na 128 bajtova oduzimanjem jedne od dužine prilikom kodiranja i dodavanjem jedne prilikom dekodiranja. Na ovaj način možemo kodirati dužine od 1 do 128 umjesto dužina od 0 do 127.
Druga stvar koju možete primijetiti je da ne postoje nizovi identičnih elemenata jedinične dužine. Stoga ćemo prilikom kodiranja od dužine takvih sekvenci oduzeti još jednu, čime ćemo povećati njihovu maksimalnu dužinu na 129 (maksimalna dužina lanca pojedinačnih elemenata je i dalje 128). One. Naši lanci identičnih elemenata mogu imati dužinu od 2 do 129.
Hajde da ponovo kodiramo naše podatke, ali sada u formi razumljivom kompjuteru. Servisne bajtove ćemo napisati kao , gdje je T tip sekvence, a L dužina. Uzmimo odmah u obzir da dužine zapisujemo u modificiranom obliku: za T=0 oduzimamo jednu od L, a za T=1 oduzimamo dvije.
0, , 4, 2, 0, , 4, , 80, , 0, , 2, , 255, , 0
Pokušajmo dekodirati naš rezultat:
- . T=1, što znači da će se sljedeći bajt ponoviti L+2 (4+2) puta: 0, 0, 0, 0, 0, 0.
- . T=0, što znači da jednostavno čitamo L+1 (2+1) bajtova: 4, 2, 0.
- . T=1, ponovite sljedeći bajt 5+2 puta: 4, 4, 4, 4, 4, 4, 4.
- . T=1, ponovite sljedeći bajt 2+2 puta: 80, 80, 80, 80.
- . T=0, čitanje 0+1 bajtova: 0.
- . T=1, ponoviti bajt 2+2 puta: 2, 2, 2, 2.
- . T=1, ponovi bajt 3+2 puta: 255, 255, 255, 255, 255.
- . T=1, ponoviti bajt 0+2 puta: 0, 0.
I sada posljednji korak: sačuvajte rezultat kao niz bajtova. Na primjer, par upakovan u bajt bi izgledao ovako:
Kao rezultat, dobijamo sljedeće:
0000: 84 00 02 04 02 00 85 04 82 80 00 00 82 02 83 FF
0010: 80
00
Na ovaj jednostavan način, koristeći ovaj primjer ulaznih podataka, dobili smo 18 bajtova od 32 bajta. Nije loš rezultat, pogotovo ako se uzme u obzir da na dužim lancima može ispasti mnogo bolje.
Moguća poboljšanja
Efikasnost algoritma zavisi ne samo od samog algoritma, već i od načina na koji se implementira. Stoga se za različite podatke mogu razviti različite varijacije kodiranja i predstavljanja kodiranih podataka. Na primjer, kada kodirate slike, možete napraviti lance promjenjive dužine: dodijelite jedan bit da označite dugačak lanac, a ako je postavljen na jedan, pohranite dužinu iu sljedećem bajtu. Na ovaj način žrtvujemo dužinu kratkih lanaca (65 elemenata umjesto 129), ali omogućavamo kodiranje lanaca dužine do 16385 elemenata (2 14 + 2) sa samo tri bajta!Dodatna efikasnost se može postići upotrebom heurističke metode kodiranje. Na primjer, kodirajmo sljedeći lanac koristeći našu metodu: "ABBA". Dobijamo " , A, , B, , A" - tj. Pretvorili smo 4 bajta u 6, naduvajući originalne podatke za čak jedan i po puta! I što je više takvih kratkih naizmjeničnih nizova različitih tipova, to je više suvišnih podataka. Ako ovo uzmemo u obzir, onda bismo rezultat mogli kodirati kao “, A, B, B, A” – potrošili bismo samo jedan dodatni bajt.
LZ77 - kratkoća u ponavljanju
LZ77 je jedan od najjednostavnijih i najpoznatijih algoritama u LZ porodici. Ime je dobio po svojim tvorcima: Abrahamu Lempelu L empel) i Jacob Ziv (Jacob Z iv). Brojevi 77 u naslovu označavaju 1977. godinu u kojoj je objavljen članak koji opisuje ovaj algoritam.Osnovna ideja je kodiranje identičnih nizova elemenata. Odnosno, ako se određeni lanac elemenata pojavljuje više puta u ulaznim podacima, onda se sva njegova naknadna pojavljivanja mogu zamijeniti „vezama“ na njegovu prvu instancu.
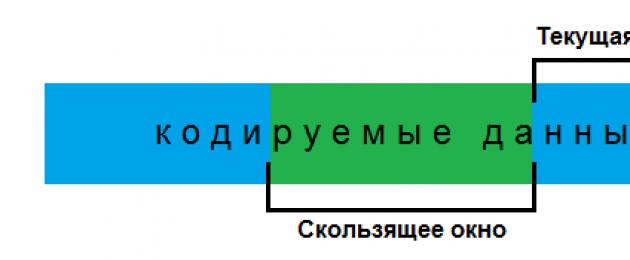
Kao i drugi algoritmi u ovoj porodici, LZ77 koristi rečnik koji pohranjuje prethodno naiđene sekvence. Da bi to učinio, primjenjuje princip tzv. "klizni prozor": područje uvijek ispred trenutne pozicije kodiranja unutar koje možemo adresirati reference. Ovaj prozor je dinamički rečnik za ovaj algoritam - svakom elementu u njemu odgovaraju dva atributa: pozicija u prozoru i dužina. Iako u fizičkog čula to je samo dio memorije koji smo već kodirali.

Primjer implementacije
Pokušajmo sada nešto kodirati. Hajde da napravimo neki odgovarajući red za ovo (unaprijed se izvinjavam zbog njegove apsurdnosti):“Kompresija i dekompresija ostavljaju utisak. Hahahahaha!”
Ovako će to izgledati u memoriji (ANSI kodiranje):
0000: 54 68 65 20 63 6F 6D 70 72 65 73 73 69 6F 6E 20 Kompresija
0010: 61 6E 64 20 74 68 65 20 64 65 63 6F 6D 70 72 65 i dekompre
0020: 73 73 69 6F 6E 20 6C 65 61 76 65 20 61 6E 20 69 godišnji odmor i
0030: 6D 70 72 65 73 73 69 6F 6E 2E 20 48 61 68 61 68 otisaka. Hahah
0040: 61 68 61 68 61 21 ahaha!
Još nismo odlučili za veličinu prozora, ali ćemo se složiti da je veći od veličine kodiranog niza. Pokušajmo pronaći sve nizove znakova koji se ponavljaju. Smatramo da je lanac niz znakova duži od jednog. Ako je lanac dio dužeg lanca koji se ponavlja, zanemarit ćemo ga.
“Kompresija i t de leave[ an] i . Hah!
Radi veće jasnoće, pogledajmo dijagram, gdje možemo vidjeti korespondenciju između ponovljenih sekvenci i njihovih prvih pojavljivanja:
Možda će jedina nejasna tačka ovdje biti sekvenca “Hahahahaha!”, jer lanac znakova “ahahaha” odgovara kratkom lancu “ah”. Ali tu nema ničeg neobičnog, koristili smo neki trik koji omogućava da algoritam ponekad radi kao RLE opisan ranije.
Činjenica je da ćemo prilikom raspakivanja pročitati navedeni broj znakova iz rječnika. A pošto je čitav niz periodičan, tj. podaci u njemu se ponavljaju sa određenim periodom, a simboli prvog perioda će se nalaziti neposredno ispred pozicije za raspakivanje, onda iz njih možemo rekreirati ceo lanac jednostavnim kopiranjem simbola prethodnog perioda u sledeći. 
To je sređeno. Sada zamijenimo pronađena ponavljanja linkovima do rječnika. Kariku ćemo napisati u formatu, gdje je P pozicija prvog pojavljivanja lanca u liniji, L njegova dužina.
“Kompresija i t de ostavljaju i. Hah!
Ali ne zaboravite da imamo posla sa kliznim prozorom. Radi boljeg razumijevanja, tako da veze ne ovise o veličini prozora, zamijenimo apsolutne pozicije razlikom između njih i trenutne pozicije kodiranja.
“Kompresija i t de ostavljaju i. Hah!
Sada samo trebamo oduzeti P od trenutne pozicije kodiranja da bismo dobili apsolutnu poziciju u nizu.
Vrijeme je da odlučite o veličini prozora i maksimalnoj dužini kodirane fraze. Budući da je riječ o tekstu, rijetko će biti posebno dugih sekvenci koje se ponavljaju. Dakle, hajde da dodijelimo, recimo, 4 bita za njihovu dužinu - ograničenje od 15 znakova odjednom nam je sasvim dovoljno.
Ali veličina prozora određuje koliko ćemo duboko tražiti identične lance. Budući da se radi o malim tekstovima, bilo bi dobro da broj bitova koje koristimo dopunimo na dva bajta: adresiraćemo veze u rasponu od 4096 bajtova, koristeći 12 bitova za to.
Iz iskustva s RLE znamo da se ne mogu koristiti sve vrijednosti. Očigledno, veza može imati minimalnu vrijednost od 1, tako da da bismo se vratili u raspon od 1..4096, moramo oduzeti jednu od veze prilikom kodiranja i dodati je natrag prilikom dekodiranja. Ista stvar sa dužinama sekvence: umesto 0..15 koristićemo opseg 2..17, pošto ne radimo sa nultim dužinama, a pojedinačni karakteri nisu sekvence.
Dakle, predstavimo naš kodirani tekst uzimajući u obzir ove izmjene:
“Kompresija i t de ostavljaju i. Hah!
Sada, opet, moramo nekako odvojiti komprimirane lance od ostatka podataka. Najčešći način je da ponovo koristite strukturu i eksplicitno naznačite gdje su podaci komprimirani, a gdje nisu. Da bismo to učinili, podijelit ćemo kodirane podatke u grupe od osam elemenata (simbola ili veza), a prije svake od ovih grupa umetnut ćemo bajt, gdje svaki bit odgovara tipu elementa: 0 za simbol i 1 za vezu.
Delimo se u grupe:
- "komp"
- "resija"
- "i t de"
- "ostavi"
- "i. hah"
"(0,0,0,0,0,0,0,0) Rezija komp(0,0,0,0,0,0,0,0) (0,0,0,0,0,1 ,0,0) i t de(1,0,0,0,0,0,1,0) ostavljaju (0,1,0,0,0,0,0,1) i . Hah (0) !”
Dakle, ako tokom raspakivanja naiđemo na bit 0, onda jednostavno čitamo karakter u izlazni tok, ako je bit 1, čitamo vezu, a iz veze čitamo sekvencu iz rječnika.
Sada sve što treba da uradimo je da grupišemo rezultat u niz bajtova. Složimo se da koristimo bitove i bajtove redoslijedom od visokog prema nižem. Pogledajmo kako se veze pakuju u bajtove koristeći primjer:
Kao rezultat toga, naš komprimirani stream će izgledati ovako:
0000: 00 54 68 65 20 63 6f 6d 70 00 72 65 73 73 69 6f #The comp#ressio
0010: 6e 20 04 61 6e 64 20 74 01 31 64 65 82 01 5a 6c n #and t##de###l
0020: 65 61 76 65 01 b1 20 41 69 02 97 2e 20 48 61 68 eave## #i##. Hah
0030: 00 15
00
21 00 00 00 00 00 00 00 00 00 00 00 00
###!
Moguća poboljšanja
U principu, ovdje će biti istina sve što je opisano za RLE. Konkretno, da biste pokazali korisnost heurističkog pristupa prilikom kodiranja, razmotrite sljedeći primjer:“Dugo goooooong. Looooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooooomnoga."
Nađimo sekvence samo za riječ “loooooower”:
“Dugo goooooong. Najbolji vezani."
Da bismo kodirali takav rezultat, potrebna su nam četiri bajta po referenci. Međutim, bilo bi ekonomičnije učiniti ovo:
“Dugo goooooong. Bio sam vezan.”
Tada bismo potrošili jedan bajt manje.
Umjesto zaključka
Uprkos svojoj jednostavnosti i naizgled ne baš efikasnim, ovi algoritmi se i dalje široko koriste u različitim oblastima IT sektora.Njihova prednost je jednostavnost i brzina, a složeniji i efikasniji algoritmi se mogu zasnivati na njihovim principima i njihovim kombinacijama.
Nadam se da će suština ovih algoritama predstavljenih na ovaj način pomoći nekome da shvati osnove i počne da gleda ka ozbiljnijim stvarima.
Run-length encoding (RLE) ili Repeat Coding je jednostavan algoritam kompresije podataka koji radi na pokretanju podataka, odnosno sekvencama u kojima se isti znak pojavljuje nekoliko puta zaredom. Prilikom kodiranja, niz identičnih znakova koji čine niz zamjenjuje se nizom koji sadrži sam karakter koji se ponavlja i broj njegovih ponavljanja.
Karakteristike RLE algoritma:
Omjeri kompresije: Prva opcija: 32, 2, 0.5. Druga opcija: 64, 3, 128/129. (Najbolje, prosječne, najgore kvote). Image class: Algoritam je fokusiran na slike sa malim brojem boja: poslovne i naučne grafike. simetrija: Oko jednog.
Karakteristike: TO pozitivni aspekti Jedino što se može pripisati algoritmu je to što ne zahtijeva dodatnu memoriju prilikom arhiviranja i raspakiranja, a radi i brzo. Zanimljiva karakteristika grupno kodiranje je da se stepen arhiviranja za neke slike može značajno povećati jednostavnom promenom redosleda boja u paleti slika.
Prva verzija algoritma
Ovaj algoritam je izuzetno jednostavan za implementaciju. Grupno kodiranje - od engleskog Run Length Encoding (RLE) - jedan je od najstarijih i najjednostavnijih algoritama za arhiviranje grafike. Slika u njemu (kao u nekoliko algoritama opisanih u nastavku) je ucrtana u lanac bajtova duž rasterskih linija. Sama kompresija u RLE-u nastaje zbog činjenice da u originalna slika postoje lanci identičnih bajtova. Zamijenite ih parovima<brojač ponavljanja, vrijednost> smanjuje redundantnost podataka.
Algoritam je dizajniran za poslovnu grafiku - slike sa velikim površinama boja koje se ponavljaju. Situacija kada datoteka raste nije tako rijetka za ovaj jednostavan algoritam. Može se lako dobiti primjenom grupnog kodiranja na obrađene fotografije u boji. Da bi se slika udvostručila, ona se mora primijeniti na sliku u kojoj su vrijednosti svih piksela veće od binarnih 11000000 i ne ponavljaju se u parovima u nizu.
Druga verzija algoritma
Druga verzija ovog algoritma ima veći maksimalni omjer arhiviranja i manje povećava veličinu originalne datoteke.
29. lzw algoritam kompresije
Algoritam je dobio ime po prvim slovima prezimena njegovih programera - Lempel, Ziv I Welch.
LZW algoritam se temelji na ideji proširenja abecede, što omogućava korištenje dodatnih znakova za predstavljanje nizova regularnih znakova. Koristeći, na primjer, 9-bitne ASCII kodove umjesto 8-bitnih, dobijate dodatnih 256 znakova. Rad kompresora se svodi na pravljenje tabele koja se sastoji od redova i njihovih odgovarajućih kodova. Algoritam kompresije se svodi na sljedeće: program čita sljedeći znak i dodaje ga nizu. Ako je red već u tabeli, čitanje se nastavlja, ako nije, zadata linija se dodaje u tabelu stringova. Što je više duplikata linija, to će podaci biti više komprimirani. Vraćajući se na primjer s telefonom, možemo, koristeći vrlo pojednostavljenu analogiju, reći da ćemo kompresijom zapisa 233 34 44 metodom LZW na kraju uvesti nove linije - 333 i 444 i, izražavajući ih dodatnim znakovima, moći ćemo smanjiti dužinu zapisa.
Karakteristike LZW algoritma:Omjeri kompresije: Približno 1000, 4, 5/7 (najbolje, prosječne, najgore kvote). Kompresija od 1000 puta se postiže samo na slikama u jednoj boji koje su višestruke veličine od približno 7 MB. Image class: LZW je fokusiran na 8-bitne slike napravljene na računaru. Kompresije zbog identičnih podlanaca u toku. Simetrija: Gotovo simetrično, pod uslovom da je operacija pretraživanja za red u tabeli optimalno implementirana.
Karakteristike: Situacija kada algoritam uvećava sliku je izuzetno rijetka. LZW je univerzalan - to su njegove varijante koje se koriste u konvencionalnim arhivima.
Proces kompresije izgleda prilično jednostavan. Čitamo znakove ulaznog toka sekvencijalno i provjeravamo da li takav niz postoji u tabeli stringova koju smo kreirali. Ako postoji red, onda čitamo sljedeći znak, a ako nema reda, onda unosimo kod za prethodni pronađeni red u stream, unosimo red u tablicu i počinjemo ponovo pretraživanje.
Posebnost LZW-a je da za dekompresiju nema potrebe da se tabela stringova sprema u datoteku za dekompresiju. Algoritam je dizajniran na takav način da možemo vratiti tabelu nizova koristeći samo niz kodova.
Priprema dokumenta
i koristite ovaj stil za formatiranje formule otkucane u LaT E X formatu.
Dizajnirajte naslov "Književnost" u stilu " Naslov 2" Navedite informacije o knjizi D. Knutha u obliku numerisane liste.
Pronađite informacije o knjizi “Sve o T E X-u” na web stranici izdavačke kuće Williams i učinite naslov knjige hipervezom na stranicu koju ste pronašli. Provjerite radi li hiperveza.
RLE algoritam
Koristeći RLE algoritam, kodirajte niz znakova
Zapišite rezultat kao heksadecimalne kodove (svaki znak je kodiran kao bajt, koji je predstavljen sa dvije heksadecimalne cifre). Provjerite rezultat pomoću RLE programa.
Dešifrirajte sekvencu upakovanu koristeći RLE algoritam (dati su heksadecimalni kodovi): 01 4D 8E 41 01 4D 8E 41 16 . Za identifikaciju znakova po njihovom heksadecimalnom kodu, koristite ASCII tablicu. Odredite broj bajtova u originalnom i raspakovanom nizu i izračunajte omjer kompresije:
Provjerite rezultat dobiven u prethodnom pasusu pomoću RLE programa. Predložite dvije metode provjere.
Konstruirajte sekvence koje su komprimirane RLE algoritmom tačno 2 puta, 4 puta, 5 puta. Provjerite svoje odgovore pomoću RLE programa.
Nekomprimovani niz
Kompresovana sekvenca
Omjer kompresije
2
4
5
Zamislite tri sekvence koje se ne mogu komprimirati pomoću RLE algoritma:
Nekomprimovani niz
"Kompresovana" sekvenca
Omjer kompresije
Koristeći RLE program, primijenite RLE kompresiju na sljedeće datoteke i pronađite omjer kompresije za svaku od njih:
File
Nekomprimovana veličina
Veličina nakon kompresije
Omjer kompresije
grad_vert.bmp
grad_horz.bmp
grad_diag.jpg
Objasnite rezultate dobijene u prethodnom pasusu:
Zašto nije korisno komprimirati slike u JPEG formatu?
Zašto su omjeri kompresije RLE tako različiti za dvije BMP slike iste veličine? Clue: Otvorite ove slike u bilo kom pregledniku.
Procijenite maksimalno dostižni omjer kompresije koristeći verziju RLE algoritma o kojoj se govori u udžbeniku. U kom slučaju će to biti moguće postići?
Procijenite omjer kompresije u najgorem slučaju koristeći RLE algoritam. Opišite ovaj najgori scenario.
Poređenje algoritama kompresije
Pokrenite program Huffman.exe i kodirajte niz "RACOON DOESN'T DROWN" koristeći Shannon-Fano i Huffman metode. Zapišite rezultate u tabelu:
| Shannon i Fano | Huffman |
|
| Dužina glavnog koda | ||
| | ||
| | ||
| |
Izvucite zaključke.
Odgovori:
Šta mislite kako će se omjer kompresije mijenjati kako se dužina teksta povećava, pod uvjetom da skup znakova i njihova učestalost ostanu nepromijenjeni? Provjerite svoj izlaz pomoću programa (na primjer, možete kopirati istu frazu nekoliko puta).
Odgovori:
Ponovite eksperiment sa frazom "NOVI RAKUN".
| Shannon i Fano | Huffman |
|
| Dužina glavnog koda | ||
| Dužina tablice kodova (stablo) | ||
| Omjer kompresije (po glavnim kodovima) | ||
| Omjer kompresije (uzimajući u obzir stablo koda) |
Izvucite zaključke.
Odgovori:
Nacrtajte u svoju bilježnicu stabla koda koja je program napravio koristeći obje metode.
Korišćenjem dugmeta Analiza fajlova u programu Huffman a.txt 1 sa bajt-bajt kodiranjem.
Korišćenje programa RLE I Huffman komprimirati datoteku a. poruka Različiti putevi. Zapišite rezultate u tabelu:
Objasnite rezultat dobiven korištenjem RLE algoritma.
Odgovori:
Korišćenjem dugmeta Analiza fajlova u programu Huffman, odredite maksimalni teoretski omjer kompresije za datoteku a.txt.huf sa bajt-bajt kodiranjem. Objasnite rezultat.
Ponovno komprimirajte ovu datoteku koristeći Huffman algoritam nekoliko puta (novi fajlovi će biti imenovani a.txt.huf2, a.txt.huf3 itd.) i ispunite tabelu, svaki put analizirajući rezultujuću datoteku.
| veličina fajla | |
|
| a.txt | ||
| a.txt.huf | ||
| a.txt.huf2 | ||
| a.txt.huf3 | ||
| a.txt.huf4 | ||
| a.txt.huf5 |
Odgovori:
Slijedite iste korake koristeći Shannon-Fano metodu.
| veličina fajla | Granični omjer kompresije |
|
| a.txt | ||
| a.txt.shf | ||
| a.txt.shf2 | ||
| a.txt.shf3 | ||
| a.txt.shf4 | ||
| a.txt.shf5 |
Objasnite zašto, nakon određenog trenutka, kada se datoteka ponovo komprimuje, njena veličina se povećava.
Odgovori:
Uporedite rezultate kompresije ove datoteke pomoću RLE algoritma, najbolje rezultate dobijene Shannon-Fano i Huffman metodama, kao i rezultat kompresije ove datoteke nekim arhivatorom.
| veličina fajla | Granični omjer kompresije |
|
| RLE | ||
| Huffman | ||
| Shannon i Fano | ||
| ZIP | ||
| RAR | ||
| 7Z |
Objasnite rezultate i izvedite zaključke.
Odgovori:
Korištenje arhivatora
Istražite mogućnosti arhivatora koji je instaliran na vašem računaru ( Ark, 7- Zip, WinRAR ili drugi).
Otvorite imenik koji je odredio nastavnik. Trebao bi sadržavati sve datoteke koje se dalje koriste.
Raspakujte arhivu tajna.zip koji je upakovan sa lozinkom secretLatin. U rezultirajućim poddirektorijumima nakon raspakivanja, trebali biste pronaći 3 datoteke koje sadrže dijelove izreke na latinskom, što znači "ugovori se moraju čuvati".
Kreirajte novu tekstualnu datoteku latin.txt i zapišite ovu izjavu latinicom. Nakon toga, obrišite arhivu secret.zip.
Komprimirajte svaku datoteku navedenu u tabeli zasebno koristeći format arhive koji je odredio nastavnik. Izračunajte omjer kompresije (zgodno je koristiti tabelu za to):
| Ime dokumenta | Opis | Jačina zvuka do kompresija, KB | Volumen nakon kompresije, KB | Omjer kompresije |
| random.dat | slučajni podaci | 391 | ||
| morning.zip | komprimovani fajl | 244 | ||
| sunset.jpg | crtanje u JPEG formatu | 730 | ||
| prog.exe | program za Windows | 163 | ||
| signal.mp3 | MP3 audio | 137 | ||
| forest.wav | zvuk u WAV formatu | 609 | ||
| ladoga.bmp | crtanje u BMP formatu | 9217 | ||
| tolstoy.txt | tekst | 5379 |
Zapišite u svoju bilježnicu svoje nalaze o tome koje datoteke se obično bolje kompresuju, a koje lošije.
Ako vam vaš arhiver dozvoljava da kreirate arhive koje se same raspakuju, uporedite veličine obične arhive i SFX arhive za datoteku masno. poruka:
Objasnite zašto su veličine ove dvije arhive različite. Nakon toga, izbrišite obje kreirane arhive.
Premjestite slike u poseban direktorij Slike, a zvučne datoteke - u direktorij Zvuci.
Pakujte slike i zvukove u arhivu Mediji sa lozinkom mediji123.
Spakujte sve ostale fajlove i fascikle u arhivu Podaci(bez lozinke).
Izbrišite sve datoteke osim arhiva Mediji I Podaci, i pokažite svoj rad nastavniku.
Kompresija sa gubitkom
Kopirajte datoteku u svoju fasciklu valaam.jpg.
Korištenje rasterskog grafičkog uređivača ( GIMP, Photoshop), sačuvajte nekoliko kopija ovog crteža različitog kvaliteta, od 0% do 100%.
| Kvalitet, % | 0 | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 |
| Veličina datoteke, KB |
Koristeći procesor za proračunske tablice, konstruirajte graf koristeći ove podatke. Izvucite zaključke.
Pregledajte fajlove dobijene sa različitim nivoima kompresije. Odaberite opciju koja je po vašem mišljenju najbolja, kada kvalitet slike ostane prihvatljiv uprkos maloj veličini datoteke.
Kopirajte zvučni fajl u svoju fasciklu medvjedi. mp3 .
Korištenje uređivača zvuka (npr. Audacity), sačuvajte više kopija ove audio datoteke različitih kvaliteta. Za format OggVorbis koristite kvalitet od 0% do 100%, za format MP3– brzina prijenosa od 16 do 128 Kbps.
Popunite tabelu u procesoru tabela
Konstruirajte graf koristeći ove podatke. Objasnite zašto je došlo do ovog konkretnog odnosa.
Slušajte fajlove dobijene na različitim nivoima kompresije. Odaberite opciju koja je po vašem mišljenju najbolja, kada veličina datoteke održava prihvatljivu kvalitetu zvuka.
Prva verzija algoritma
Ovaj algoritam je izuzetno jednostavan za implementaciju. Grupno kodiranje - od engleskog Run Length Encoding (RLE) - jedan je od najstarijih i najjednostavnijih algoritama za arhiviranje grafike. Slika u njemu (kao u nekoliko algoritama opisanih u nastavku) je ucrtana u lanac bajtova duž rasterskih linija. Dolazi do same kompresije u RLE-u zbog činjenice da izvorna slika sadrži lance identičnih bajtova. Zamijenite ih parovima<счетчик повторений, значение>smanjuje redundantnost podataka.
Algoritam dekompresija izgleda ovako:
Inicijalizacija(...);
učiniti (
if(je brojač(bajt)) (
brojač = Low6bits(byte)+1;
for(i=1 do brojača)
De
}
drugo(
DecompressedFile.WriteByte(byte)
) while(Datoteka slike.EOF());
U ovom algoritmu, predznak brojača su oni u dva gornja bita pročitane datoteke:
Shodno tome, preostalih 6 bitova se troši na brojač koji može imati vrijednosti od 1 do 64. Niz od 64 bajta koji se ponavljaju pretvaramo u dva bajta, tj. Komprimirajmo ga 32 puta.
vježba: Kreirajte algoritam kompresija za prvu verziju RLE algoritma.
Algoritam je dizajniran za poslovnu grafiku - slike sa velikim površinama boja koje se ponavljaju. Situacija kada datoteka raste nije tako rijetka za ovaj jednostavan algoritam. Može se lako dobiti primjenom grupnog kodiranja na obrađene fotografije u boji. Da bi se slika udvostručila, ona se mora primijeniti na sliku u kojoj su vrijednosti svih piksela veće od binarnih 11000000 i ne ponavljaju se u parovima u nizu.Pitanje za samokontrolu: Ponudite dva ili tri primjera “loših” slika za RLE algoritam. Objasnite zašto je komprimirana datoteka veća od originalne datoteke.
Ovaj algoritam je implementiran u PCX formatu. Vidi na primjer dodatak.Druga verzija algoritma
Druga verzija ovog algoritma ima veći maksimalni omjer arhiviranja i manje povećava veličinu originalne datoteke.
Algoritam dekompresije za to izgleda ovako:
Inicijalizacija(...);
učiniti (
byte = ImageFile.ReadNextByte();
brojač = Low7bits(byte)+1;
if(ako ponovi zastavicu(bajt)) (
vrijednost = ImageFile.ReadNextByte();
za (i=1 do brojača)
CompressedFile.WriteByte(vrijednost)
}
drugo(
for(i=1 do brojača)(
vrijednost = ImageFile.ReadNextByte();
CompressedFile.WriteByte(vrijednost)
}
CompressedFile.WriteByte(byte)
) while(Datoteka slike.EOF());
Znak ponavljanja u ovom algoritmu je jedan u najznačajnijem bitu odgovarajućeg bajta:

Kao što možete lako izračunati, u najboljem slučaju ovaj algoritam komprimuje datoteku 64 puta (a ne 32 puta, kao u prethodnoj verziji), u najgorem slučaju, povećava je za 1/128. Prosječni omjer kompresije ovog algoritma je na nivou prve opcije.
vježba: Kreirajte algoritam kompresije za drugu verziju RLE algoritma.
Slične šeme kompresije koriste se kao jedan od podržanih algoritama TIFF format, kao i u TGA formatu.Karakteristike RLE algoritma:
Omjeri kompresije: Prva opcija: 32, 2, 0,5. Druga opcija: 64, 3, 128/129.(najbolje, prosječne, najgore kvote)
Klasa slike: Algoritam je fokusiran na slike sa malim brojem boja: poslovne i naučne grafike.
Simetrija: otprilike jedan.
Karakteristične karakteristike: Jedina pozitivna strana algoritma je, možda, to što ne zahtijeva dodatnu memoriju prilikom arhiviranja i raspakiranja, a radi i brzo. Zanimljiva karakteristika paketnog kodiranja je da se stepen arhiviranja nekih slika može značajno povećati jednostavnom promenom redosleda boja u paleti slika.
LZW algoritamAlgoritam je dobio ime po prvim slovima prezimena njegovih programera - Lempel, Ziv i Welch. Kompresija u njemu, za razliku od RLE-a, vrši se pomoću identičnih lanaca bajtova.
LZ algoritam
Postoji prilično velika porodica algoritama sličnih LZ-u, koji se razlikuju, na primjer, u metodi traženja lanaca koji se ponavljaju. Jedan od dovoljnih jednostavne opcije Ovaj algoritam, na primjer, pretpostavlja da ulazni tok sadrži ili par<счетчик, смещение относительно текущей позиции>, ili samo<счетчик>"preskočenih" bajtova i bajt vrijednosti sami sebe (kao u drugoj verziji RLE algoritma). Prilikom otkopčavanja za par<счетчик, смещение>kopirano<счетчик>bajt iz izlaznog niza dobivenog kao rezultat raspakivanja, to<смещение>bajt prije<счетчик>(tj. broj jednak brojaču) vrijednosti bajtova za „preskakanje“ se jednostavno kopiraju u izlazni niz iz ulaznog toka. Ovaj algoritam je asimetričan u vremenu, jer zahtijeva potpunu pretragu bafera kada se traže identični podnizovi. Kao rezultat toga, teško nam je odrediti veliki bafer zbog naglog povećanja vremena kompresije. Međutim, potencijalna izgradnja algoritma u kojem<счетчик>i dalje<смещение>2 bajta će biti dodijeljena (najznačajniji bit visokog bajta brojača je znak ponavljanja linije / kopiranja toka), dajući nam priliku da kompresujemo sve ponovljene podnizove veličine do 32Kb u baferu od 64Kb.
U ovom slučaju, dobićemo povećanje veličine fajla u najgorem slučaju za 32770/32768 (u dva bajta piše da narednih 2 15 bajta treba prepisati u izlazni tok), što uopće nije loše . Maksimalni omjer kompresije bit će 8192 puta. U limitu, pošto postižemo maksimalnu kompresiju pretvaranjem bafera od 32Kb u 4 bajta, i nećemo akumulirati bafer ove veličine odmah. Međutim, minimalni podniz za koji je korisno da izvršimo kompresiju generalno treba da se sastoji od najmanje 5 bajtova, što određuje nisku vrednost ovog algoritma. Prednosti LZ-a uključuju ekstremnu jednostavnost algoritma za dekompresiju.
vježba: Predložite drugu verziju LZ algoritma, u kojoj za par<счетчик, смещение>3 bajta će se dodijeliti i izračunati glavne karakteristike vašeg algoritma.
LZW algoritamVarijanta algoritma koju razmatramo u nastavku će koristiti stablo za predstavljanje i pohranjivanje lanaca. Očigledno, ovo je prilično jako ograničenje za tip lanaca, a neće se svi identični podlanci na našoj slici koristiti tokom kompresije. Međutim, u predloženom algoritmu je korisno komprimirati čak i lance koji se sastoje od 2 bajta.
Proces kompresije izgleda prilično jednostavan. Čitamo znakove ulaznog toka sekvencijalno i provjeravamo da li takav niz postoji u tabeli stringova koju smo kreirali. Ako postoji red, onda čitamo sljedeći znak, a ako nema reda, onda unosimo kod za prethodni pronađeni red u stream, unosimo red u tablicu i počinjemo ponovo pretraživanje.
Funkcija InitTable() briše tabelu i stavlja sve redove jedinične dužine u nju.
InitTable();
CompressedFile.WriteCode(ClearCode);
CurStr=prazan string;
while(ne ImageFile.EOF())( //Do kraja datoteke
C=ImageFile.ReadNextByte();
if(CurStr+C je u tabeli)
CurStr=CurStr+C;//Zalijepite znak u niz
drugo(
code=CodeForString(CurStr);//kod nije bajt!
AddStringToTable(CurStr+C);
CurStr=S; // Niz od jednog znaka
}
}
code=CodeForString(CurStr);
CompressedFile.WriteCode(code);
CompressedFile.WriteCode(CodeEndOfInformation);
Kao što je gore objašnjeno, funkcija InitTable() inicijalizira tablicu stringova da sadrži sve moguće nizove od jednog znaka. Na primjer, ako komprimujemo bajt podatke, tada će u tabeli biti 256 takvih redova (“0”, “1”, ..., “255”). Za ClearCode i kraj informacijskog koda (CodeEndOfInformation) rezervirane su vrijednosti 256 i 257. U razmatranoj verziji algoritma koristi se 12-bitni kod i, shodno tome, za kodove za linije ostaje nam. sa vrijednostima od 258 do 4095. Dodati redovi se upisuju u tabelu sekvencijalno, pri čemu indeks reda u tabeli postaje njen kod.
Funkcija ReadNextByte() čita znak iz datoteke. Funkcija WriteCode() piše kod (koji nije jednak po veličini bajtu) u izlaznu datoteku. Funkcija AddStringToTable() dodaje novi red u tablicu dodjeljivanjem koda. Osim toga, ova funkcija obrađuje situacije prekoračenja tablice. U ovom slučaju, kod prethodnog pronađenog reda i kod za brisanje se upisuju u tok, nakon čega se tabela briše pomoću funkcije InitTable(). Funkcija CodeForString() pronalazi niz u tabeli i ispisuje kod za taj niz.
primjer:
Komprimirajmo sekvencu 45, 55, 55, 151, 55, 55, 55. Zatim ćemo, prema gore navedenom algoritmu, prvo staviti kod za čišćenje u izlazni tok<256>, zatim dodajte "45" u prvobitno prazan red i provjerite da li je red "45" u tabeli. Pošto smo prilikom inicijalizacije uneli u tabelu sve redove od jednog znaka, red „45“ je u tabeli. Zatim čitamo sljedeći znak 55 iz ulaznog toka i provjeravamo da li se string “45, 55” nalazi u tabeli. U tabeli još nema takvog reda. U tabelu unosimo red "45, 55" (sa prvim slobodnim kodom 258) i upisujemo kod u stream<45>. Ukratko možete zamisliti arhiviranje ovako:
- “45” - nalazi se u tabeli;
- “45, 55” - br. Dodajte u tabelu<258>“45, 55.” Za prijenos:<45>;
- “55, 55” - br. do stola:<259>“55, 55.” Za prijenos:<55>;
- “55, 151” - br. do stola:<260>“55, 151.” Za prijenos:<55>;
- “151, 55” - br. do stola:<261>“151, 55.” Za prijenos:<151>;
- “55, 55” - nalazi se u tabeli;
- “55, 55, 55” - br. Do stola: “55, 55, 55”<262>. Za prijenos:<259>;
Posebnost LZW-a je u tome što za dekompresiju ne trebamo spremiti tabelu stringova u datoteku za dekompresiju. Algoritam je dizajniran na takav način da možemo vratiti tabelu nizova koristeći samo niz kodova.
Znamo da za svaki kod trebamo dodati red u tablicu, koji se sastoji od reda koji je tamo već prisutan i znaka kojim počinje sljedeći red u toku.

Algoritam dekompresije koji izvodi ovu operaciju je sljedeći:
code=File.ReadCode();
while(code != CodeEndOfInformation)(
if(code = ClearCode) (
InitTable();
code=File.ReadCode();
if(code = CodeEndOfInformation)
(Završi posao);
ImageFile.WriteString(StrFromTable(code));
old_code=code;
}
drugo(
if(InTable(code)) (
ImageFile.WriteString(FromTable(code));
AddStringToTable(StrFromTable(old_code)+
FirstChar(StrFromTable(code)));
old_code=code;
}
drugo(
OutString= StrFromTable(old_code)+
FirstChar(StrFromTable(old_code));
ImageFile.WriteString(OutString);
AddStringToTable(OutString);
old_code=code;
}
}
}
Ovdje funkcija ReadCode() čita sljedeći kod iz dekomprimirane datoteke. Funkcija InitTable() obavlja iste radnje kao i tokom kompresije, tj. briše tabelu i upisuje sve redove istog znaka u nju. Funkcija FirstChar() nam daje prvi znak niza. Funkcija StrFromTable() vraća red iz tablice koristeći kod. Funkcija AddStringToTable() dodaje novi red u tablicu (dajući joj prvi besplatni kod). Funkcija WriteString() zapisuje string u datoteku.
Napomena 1. Kao što ste možda primijetili, kodovi upisani u stream postepeno se povećavaju. Dok se kod 512 ne pojavi u tabeli, na primer, po prvi put, svi kodovi će biti manji od 512. Osim toga, tokom kompresije i dekompresije, kodovi u tabeli se dodaju prilikom obrade istog znaka, tj. dešava se „sinhrono“. Možemo koristiti ovo svojstvo algoritma da povećamo stepen kompresije. Dok se 512. znak ne doda u tabelu, pisaćemo 9-bitne kodove u izlazni tok bitova, a odmah nakon dodavanja 512 - 10-bitne kodove. Shodno tome, dekompresor će također morati da percipira sve ulazne kodove kao 9-bitne dok se kod 512 ne doda u tablicu, nakon čega će sve ulazne kodove percipirati kao 10-bitne. Isto ćemo učiniti kada u tabelu dodamo kodove 1024 i 2048. Ova tehnika nam omogućava da povećamo stepen kompresije za otprilike 15%.

Napomena 2. Prilikom komprimiranja slike važno nam je osigurati brzinu pretraživanja redova u tabeli. Možemo iskoristiti činjenicu da je svaki sljedeći podniz jedan znak duži od prethodnog, osim toga, prethodni red smo već pronašli u tabeli. Stoga je dovoljno napraviti listu referenci na redove koji počinju sa datim podnizom, a cijeli proces pretraživanja u tabeli će se svesti na pretragu u redovima sadržanim u listi za prethodni red. Jasno je da se takva operacija može izvesti vrlo brzo.
Imajte na umu i da nam je u stvarnosti dovoljno da pohranimo samo par u tabeli<код предыдущей подстроки, добавленный символ>. Ova informacija je sasvim dovoljna da algoritam radi. Dakle, niz od 0 do 4095 sa elementima<код предыдущей подстроки; добавленный символ; список ссылок на строки, начинающиеся с этой строки>rješava zadati problem pretraživanja, iako vrlo sporo.
U praksi se za pohranjivanje tablice koristi rješenje hash table koje je jednako brzo kao u slučaju lista, ali kompaktnije u memoriji. Tabela se sastoji od 8192 (2 13) elemenata. Svaki element sadrži<код предыдущей подстроки; добавленный символ; код этой строки>. 20-bitni ključ za pretraživanje formira se korištenjem prva dva elementa pohranjena u tabeli kao jedan broj (ključ). Donjih 12 bitova ovog broja dato je kodu, a sljedećih 8 bita vrijednosti simbola.
Sljedeće se koristi kao hash funkcija:
Indeks(ključ)= ((ključ >> 12) ^ ključ) & 8191;
Gdje je >> pomak po bitu udesno (ključ >> 12 - dobijamo vrijednost karaktera), ^ je logička operacija isključivanja po bitovima ILI, & je logičko bitsko I.
Tako u nekoliko poređenja dobijamo traženi kod ili poruku da u tabeli nema tog koda.
Hajde da izračunamo najbolji i najgori omjer kompresije za ovaj algoritam. Najbolji koeficijent će se očito dobiti za dugačak lanac identičnih bajtova (tj. za 8-bitnu sliku, čiji svi pikseli imaju, sa sigurnošću, boju 0). U ovom slučaju, u 258. red tabele upisaćemo niz "0, 0", u 259 - "0, 0, 0", ... u 4095 - niz od 3839 (=4095-256) nula . U ovom slučaju, tok će sadržavati (provjerite algoritam!) 3840 kodova, uključujući kod za brisanje. Stoga, izračunavanjem sume aritmetičke progresije od 2 do 3839 (tj. dužina komprimovanog lanca) i dijeljenjem sa 3840*12/8 (12-bitni kodovi se upisuju u tok), dobijamo najbolju kompresiju odnos.
vježba: Izračunajte tačnu vrijednost najboljeg omjera kompresije. Teži zadatak: izračunajte isti koeficijent uzimajući u obzir napomenu 1.
Najgori koeficijent ćemo dobiti ako nikada ne naiđemo na podniz koji se već nalazi u tabeli (u njoj ne bi trebalo biti niti jedan identičan par karaktera).vježba: Kreirajte algoritam za generiranje takvih lanaca. Pokušajte komprimirati rezultirajuću datoteku pomoću standardnih arhivatora (zip, arj, gz). Ako dobijete kompresiju, algoritam generiranja je pogrešno napisan.
Ako stalno nailazimo na novi podniz, upisaćemo 3840 kodova u izlazni tok, što će odgovarati nizu od 3838 znakova. Bez uzimanja u obzir napomene 1, ovo će biti povećanje fajla za skoro 1,5 puta.LZW je implementiran u GIF i TIFF formatima.
Karakteristike algoritma LZW:
Omjeri kompresije: Približno 1000, 4, 5/7 (najbolji, prosječni, najgori omjeri). Kompresija od 1000 puta se postiže samo na slikama u jednoj boji koje su višestruke veličine od približno 7 MB.
Klasa slike: LZW je fokusiran na 8-bitne slike napravljene na računaru. Kompresije zbog identičnih podlanaca u toku.
simetrija: Gotovo simetrično, pod uslovom da je operacija pretraživanja za red u tabeli optimalno implementirana.
karakteristike: Situacija kada algoritam uvećava sliku izuzetno je rijetka. LZW je univerzalan - to su njegove varijante koje se koriste u konvencionalnim arhivima.
Huffmanov algoritamKlasični Huffmanov algoritam
Jedan od klasičnih algoritama poznatih od 60-ih godina. Koristi samo učestalost pojavljivanja identičnih bajtova na slici. Dodjeljuje znakove ulaznog toka koji se javljaju više puta nizu bitova kraće dužine. I, naprotiv, rijetko - lanac veće dužine. Za prikupljanje statistike potrebna su dva prijelaza preko slike.
Prvo, uvedemo nekoliko definicija.
Definicija. Neka je abeceda Y =( a 1 , ..., a r ), koji se sastoji od konačnog broja slova. Konačan niz znakova iz Y
zvaćemo jednom riječju na abecedi Y i broj n - dužina reči A. Dužina riječi se označava kao l(A).
Neka je data abeceda W, W =( b 1 , ..., b q ). Kroz B označavaju riječ u abecedi W i sa S (W)je skup svih nepraznih riječi u abecedi W.
Neka S =S(Y) -skup svih nepraznih riječi u abecedi Y, i S"- neki podskup skupa S. Neka je također dato preslikavanje F, što svaka riječ AA? S(Y)
, odgovara riječi B=F(A), B .
? S(W) Riječ IN zvaćemo kod poruke A A, i prijelaz iz riječi na njegov kod -.
Definicija. kodiranje
Razmotrimo korespondenciju između slova abecede Y i nekih riječi abecede W: 1
- B
1
,
Razmotrimo korespondenciju između slova abecede Y i nekih riječi abecede W: 2
- B
2
,
. . .
Razmotrimo korespondenciju između slova abecede Y i nekih riječi abecede W: a B r-
r Ova korespondencija se zove shema S" (W)=S (W)i označeno sa S. Definira kodiranje na sljedeći način: svaka riječ iz odgovara riječi koja se zove kod riječi B 1 ... B A. Riječi su pozvani elementarni kodovi. Ova vrsta kodiranja se zove abecedno kodiranje.
Definicija. Pusti riječ Riječ izgleda kao
B=B" B"
Onda reč B" pozvao početak ili prefiks reči B, a B" - kraj reči B. Štaviše, prazna riječ L i sama riječ B smatraju se počecima i krajevima riječi B .
Definicija .Šema S ima svojstvo prefiksa, ako za bilo kojii I j(1? i , j? r, i? j) riječ B inije prefiks riječi B j.
Teorema 1. Ako je shema S ima svojstvo prefiksa, tada će alfabetsko kodiranje biti jedan prema jedan.
Pretpostavimo da je abeceda Y =( a 1 ,..., a r} (r >1 ) i skup vjerovatnoća str 1 , . . . , str A. Riječi izgled likova a 1 ,..., a r. Neka je, dalje, data abeceda W , W =( b 1 , ..., b q} (q >1 ). Tada je moguće konstruisati čitav niz abecednih shema kodiranja S
a 1
- B
1
,
. . .
Razmotrimo korespondenciju između slova abecede Y i nekih riječi abecede W: a B r-
posjedovanje svojstva jedan-na-jedan.
Za svaki uzorak možete unijeti prosječnu dužinu l sri , definiran kao matematičko očekivanje dužine osnovnog koda:
![]() - dužina riječi.
- dužina riječi.
Dužina l sri pokazuje koliko se puta povećava prosječna dužina riječi kada se kodira shemom S.
To se može pokazati l sri dostigne svoju minimalnu vrijednost l * na nekom S i definiran je kao
Definicija . Kodovi definirani krugom S sal avg = l * , su pozvani kodovi sa minimalnom redundantnošću, ili Huffman kodovi.
Kodovi sa minimalnom redundantnošću daju, u prosjeku, minimalno povećanje dužine riječi kada se kodiraju u skladu s tim.
U našem slučaju, abeceda Y =( a 1 ,..., a r) specificira simbole ulaznog toka, a abeceda W = (0,1), tj. sastoji se samo od nule i jedan.
Algoritam za konstruisanje kola S može se predstaviti na sledeći način:
Korak 1. Sva slova ulazne abecede raspoređujemo u opadajućem redoslijedu vjerovatnoće. Brojimo sve podudarne riječi B iiz abecede W =(0,1) su prazne.
Korak 2. Kombinacija dva simbola a i r-1 I a i rnajmanje vjerovatno p i r-1 I p i rdo pseudokaraktera a"{a i r-1 zrak ) sa vjerovatnoćom p i r-1+p i r. Dodajte 0 na početak riječi B i r-1(B i r-1=0B i r-1 ), i 1 na početak riječi B i r(B i r=1B i r).
Korak 3. Uklanjanje sa liste naručenih znakova a i r-1 I a i r, stavite pseudo-simbol tamo a"{a i r-1 zrak ). Izvršite korak 2, dodajući 1 ili nulu za sve riječi ako je potrebno B i, što odgovara pseudo-znakovima, sve dok 1 pseudo-znak ne ostane na listi.
primjer: Neka imamo 4 slova u abecedi Y =( a 1 ,..., a 4 } (r =4 ), str 1 =0.5, str 2 =0.24,str 3 =0.15,str 4 =0,11 . Tada se proces konstruisanja dijagrama može predstaviti na sljedeći način:

Izvođenjem radnji koje odgovaraju 2. koraku, dobijamo pseudo-simbol sa vjerovatnoćom 0,26 (i dodijelimo 0 i 1 odgovarajućim riječima). Ponavljanjem ovih koraka za modifikovanu listu dobijamo pseudo-simbol sa verovatnoćom 0,5. I konačno, u posljednjoj fazi dobijamo ukupnu vjerovatnoću od 1.
Da bismo vratili riječi kodiranja, moramo pratiti strelice od početnih simbola do kraja rezultirajućeg binarnog stabla. Dakle, za simbol sa vjerovatnoćom str
4, dobijamo B 4 =101, for str 3 dobijamo B 3 =100, for str 2 dobijamo B 2 =11, for str 1 dobijamo B 1 =0. Šta dijagram znači:
Razmotrimo korespondenciju između slova abecede Y i nekih riječi abecede W: 1
- 0,
Razmotrimo korespondenciju između slova abecede Y i nekih riječi abecede W: 2
- 11
Razmotrimo korespondenciju između slova abecede Y i nekih riječi abecede W: 3
- 100
Razmotrimo korespondenciju između slova abecede Y i nekih riječi abecede W: 4
- 101
Ova šema je prefiksni kod koji je Huffmanov kod. Najčešći lik u streamu a
1
najkraću riječ ćemo kodirati kao 0, a najrjeđu a
4
duga riječ 101.
Za niz od 100 znakova u kojem je znak a
1
će se pojaviti 50 puta, simbol a
2
- 24 puta, simbol a
3
- 15 puta, i simbol a
4
- 11 puta, ovaj kod će vam omogućiti da dobijete sekvencu od 176 bita ( ![]() ). One. u prosjeku ćemo potrošiti 1,76 bita po simbolu toka.
). One. u prosjeku ćemo potrošiti 1,76 bita po simbolu toka.
Za dokaz teoreme, kao i činjenicu da konstruirano kolo zapravo definira Huffmanov kod, vidi.
Kao što je postalo jasno iz gore navedenog, klasični Huffmanov algoritam zahtijeva snimanje tablice korespondencije između kodiranih znakova i lanaca kodiranja u datoteku.
U praksi se koriste njegove sorte. Dakle, u nekim slučajevima je razumno ili koristiti konstantnu tabelu ili je izgraditi „adaptivno“, tj. tokom arhiviranja/dearhiviranja. Ove tehnike nas spašavaju od potrebe da dvaput prolazimo kroz sliku i da pohranjujemo tabelu zajedno sa datotekom. Fiksno kodiranje tabele se koristi kao poslednji korak arhiviranja u JPEG-u i algoritmu CCITT Grupe 3 o kome se govori u nastavku.
Karakteristike klasičnog Huffman algoritma:
Omjeri kompresije: 8, 1,5, 1 (najbolje, prosječne, najgore kvote).
Klasa slike: Praktično se ne primjenjuje na slike u njihovom čistom obliku. Obično se koristi kao jedna od faza kompresije u složenijim krugovima.
simetrija: 2 (zbog činjenice da zahtijeva dva prolaza kroz komprimirani niz podataka).
karakteristike: Jedini algoritam koji ne povećava veličinu izvornih podataka u najgorem slučaju (osim potrebe za pohranjivanjem tablice konverzije zajedno sa datotekom).
Huffmanov algoritam sa fiksnom tablicom CCITTGroup 3Slična modifikacija algoritma se koristi kada se kompresuju crno-bijele slike (jedan bit po pikselu). Puni naziv ovog algoritma je CCITT Group 3. To znači da je ovaj algoritam predložila treća grupa za standardizaciju Konsultativnog komiteta za međunarodni telegraf i telefon. Nizovi uzastopnih crnih i bijelih tačaka u njemu zamjenjuju se brojem jednakim njihovom broju. A ova serija je, zauzvrat, komprimirana prema Huffmanu s fiksnom tablicom.
Definicija: Zove se skup uzastopnih piksela slike iste boje serije.Dužina ovog skupa tačaka se zove dužina serije.
Tabela ispod sadrži dvije vrste kodova:
- Kodovi završetka serije- postavite od 0 do 63 u koracima od 1.
- Složeni (dodatni) kodovi- postavljeno sa 64 na 2560 u koracima od 64.
U praksi, u slučajevima kada je slika pretežno crna, mi invertujemo sliku prije kompresije i upisujemo informacije o tome u zaglavlje datoteke.
Algoritam kompresije izgleda ovako:
za (preko svih redova slike) (
Hajde da transformišemo string u skup dužina pokretanja;
za (preko svih serija) (
if(serija bijela) (
L= dužina vožnje;
while(L > 2623) ( // 2623=2560+63
L=L-2560;
WriteWhiteCodeFor(2560);
}
if(L > 63) (
L2=MaksimalniConstCodeLessL(L);
L=L-L2;
WriteWhiteCodeFor(L2);
}
WriteWhiteCodeFor(L);
//Ovo je uvijek izlazni kod
}
drugo(
[Šifra je slična bijeloj seriji,
s tom razlikom što su snimljeni
crni kodovi]
}
}
// Kraj linije slike
}
Pošto se crno-bijele serije izmjenjuju, kod za bijelu seriju i kod za crnu seriju će zapravo raditi naizmjenično.
U smislu regularnih izraza, dobićemo za svaki red naše slike (dovoljno dug, počevši od bele tačke) izlazni tok bitova u obliku:
((<Б-2560>)*[<Б-сст.>]<Б-зв.>(<Ч-2560>)*[<Ч-сст.>]<Ч-зв.>) +
[(<Б-2560>)*[<Б-сст.>]<Б-зв.>]
Gdje ()* - ponoviti 0 ili više puta, () + .- ponoviti 1 ili više puta, - uključiti 1 ili 0 puta.
Za prethodni primjer: 0, 3, 556, 10... algoritam će generirati sljedeći kod:<Б-0><Ч-3><Б-512><Б-44><Ч-10>, ili, prema tabeli, 00110101 10 0110010100101101 0000100 (različiti kodovi u niti su istaknuti radi praktičnosti). Ovaj kod ima svojstvo prefiksnih kodova i lako se može saviti nazad u niz dužina pokretanja. Lako je izračunati da smo za dati niz od 569 bita dobili kod dug 33 bita, tj. omjer kompresije je otprilike 17 puta.
Pitanje: Koliko puta će se povećati veličina datoteke u najgorem slučaju? Zašto? (Odgovor dat u karakteristikama algoritma nije potpun, jer su moguće veće vrijednosti najgoreg omjera kompresije. Pronađite ih.)
Imajte na umu da je jedini “složeni” izraz u našem algoritmu: L2=MaximumAdditionCodeLessL(L) - u praksi radi vrlo jednostavno: L2=(L>>6)*64, gdje je >> pomak L u bitovima ulijevo za 6 bita (možete učiniti isto za jednu bitnu operaciju & - logičko I).vježba: Dat je niz slike, napisan kao dužine pokretanja - 442, 2, 56, 3, 23, 3, 104, 1, 94, 1, 231, 120 bajtova veličine ((442+2+..+231)/8) . Izračunajte omjer kompresije ovog niza koristeći CCITT Group 3 algoritam.
Tabele u nastavku su napravljene korištenjem klasičnog Huffman algoritma (zasebno za dužine crnih i bijelih serija). Analizom velikog broja faksimilnih slika dobijene su vjerovatnoće pojave za određene dužine ciklusa.Tabela kodova završetka:
| Dužina
serije |
Bijeli kod
podnizovi |
Šifra crna
podnizovi |
Dužina
serije |
Bijeli kod
podnizovi |
Šifra crna
podnizovi |
|
| 0 | 00110101 | 0000110111 | 32 | 00011011 | 000001101010 | |
| 1 | 00111 | 010 | 33 | 00010010 | 000001101011 | |
| 2 | 0111 | 11 | 34 | 00010011 | 000011010010 | |
| 3 | 1000 | 10 | 35 | 00010100 | 000011010011 | |
| 4 | 1011 | 011 | 36 | 00010101 | 000011010100 | |
| 5 | 1100 | 0011 | 37 | 00010110 | 000011010101 | |
| 6 | 1110 | 0010 | 38 | 00010111 | 000011010110 | |
| 7 | 1111 | 00011 | 39 | 00101000 | 000011010111 | |
| 8 | 10011 | 000101 | 40 | 00101001 | 000001101100 | |
| 9 | 10100 | 000100 | 41 | 00101010 | 000001101101 | |
| 10 | 00111 | 0000100 | 42 | 00101011 | 000011011010 | |
| 11 | 01000 | 0000101 | 43 | 00101100 | 000011011011 | |
| 12 | 001000 | 0000111 | 44 | 00101101 | 000001010100 | |
| 13 | 000011 | 00000100 | 45 | 00000100 | 000001010101 | |
| 14 | 110100 | 00000111 | 46 | 00000101 | 000001010110 | |
| 15 | 110101 | 000011000 | 47 | 00001010 | 000001010111 | |
| 16 | 101010 | 0000010111 | 48 | 00001011 | 000001100100 | |
| 17 | 101011 | 0000011000 | 49 | 01010010 | 000001100101 | |
| 18 | 0100111 | 0000001000 | 50 | 01010011 | 000001010010 | |
| 19 | 0001100 | 00001100111 | 51 | 01010100 | 000001010011 | |
| 20 | 0001000 | 00001101000 | 52 | 01010101 | 000000100100 | |
| 21 | 0010111 | 00001101100 | 53 | 00100100 | 000000110111 | |
| 22 | 0000011 | 00000110111 | 54 | 00100101 | 000000111000 | |
| 23 | 0000100 | 00000101000 | 55 | 01011000 | 000000100111 | |
| 24 | 0101000 | 00000010111 | 56 | 01011001 | 000000101000 | |
| 25 | 0101011 | 00000011000 | 57 | 01011010 | 000001011000 | |
| 26 | 0010011 | 000011001010 | 58 | 01011011 | 000001011001 | |
| 27 | 0100100 | 000011001011 | 59 | 01001010 | 000000101011 | |
| 28 | 0011000 | 000011001100 | 60 | 01001011 | 000000101100 | |
| 29 | 00000010 | 000011001101 | 61 | 00110010 | 000001011010 | |
| 30 | 00000011 | 000001101000 | 62 | 00110011 | 000001100110 | |
| 31 | 00011010 | 000001101001 | 63 | 00110100 | 000001100111 |
Tabela kompozitnih kodova:
| Dužina
serije |
Bijeli kod
podnizovi |
Šifra crna
podnizovi |
Dužina
serije |
Bijeli kod
podnizovi |
Šifra crna
podnizovi |
|
| 64 | 11011 | 0000001111 | 1344 | 011011010 | 0000001010011 | |
| 128 | 10010 | 000011001000 | 1408 | 011011011 | 0000001010100 | |
| 192 | 01011 | 000011001001 | 1472 | 010011000 | 0000001010101 | |
| 256 | 0110111 | 000001011011 | 1536 | 010011001 | 0000001011010 | |
| 320 | 00110110 | 000000110011 | 1600 | 010011010 | 0000001011011 | |
| 384 | 00110111 | 000000110100 | 1664 | 011000 | 0000001100100 | |
| 448 | 01100100 | 000000110101 | 1728 | 010011011 | 0000001100101 | |
| 512 | 01100101 | 0000001101100 | 1792 | 00000001000 | slučajnost sa bijelim | |
| 576 | 01101000 | 0000001101101 | 1856 | 00000001100 | - // - | |
| 640 | 01100111 | 0000001001010 | 1920 | 00000001101 | - // - | |
| 704 | 011001100 | 0000001001011 | 1984 | 000000010010 | - // - | |
| 768 | 011001101 | 0000001001100 | 2048 | 000000010011 | - // - | |
| 832 | 011010010 | 0000001001101 | 2112 | 000000010100 | - // - | |
| 896 | 011010011 | 0000001110010 | 2176 | 000000010101 | - // - | |
| 960 | 011010100 | 0000001110011 | 2240 | 000000010110 | - // - | |
| 1024 | 011010101 | 0000001110100 | 2304 | 000000010111 | - // - | |
| 1088 | 011010110 | 0000001110101 | 2368 | 000000011100 | - // - | |
| 1152 | 011010111 | 0000001110110 | 2432 | 000000011101 | - // - | |
| 1216 | 011011000 | 0000001110111 | 2496 | 000000011110 | - // - | |
| 1280 | 011011001 | 0000001010010 | 2560 | 000000011111 | - // - |
Ovaj algoritam je implementiran u TIFF formatu.
Karakteristike algoritma CCITT grupa 3
PROFIL Prilikom kompresije pomoću RLE algoritma prvo se bilježi broj ponavljanja prvog znaka, zatim samog prvog znaka, zatim broj ponavljanja drugog znaka itd. U ovom slučaju, cijeli kodirani fajl zauzima 4 bajta: 0 11 00100 2 11 000000 2 011 00100 2 11 000001 2 100 A (šifra 192) 100 B (šifra 193) Dakle, komprimirali smo datoteku 50 puta zbog činjenice da je opet imao redundanciju - lance identičnih znakova. Ovo je kompresija bez gubitaka jer, poznavajući algoritam pakovanja, možete oporaviti originalne podatke iz koda. Očigledno, ovaj pristup će dovesti do povećanja (za 2 puta) količine podataka u slučaju kada u datoteci nema susjednih identičnih znakova. Da bi se poboljšali rezultati RLE kodiranja čak iu ovom najgorem slučaju, algoritam je modificiran na sljedeći način. Pakovana sekvenca sadrži kontrolne bajtove, svaki kontrolni bajt praćen jednim ili više bajtova podataka. Ako je najznačajniji bit kontrolnog bajta 1, tada se bajt podataka koji slijedi nakon kontrolnog bajta tokom raspakivanja mora ponoviti onoliko puta koliko je zapisano u preostalih 7 bitova kontrolnog bajta. Ako je najznačajniji bit kontrolnog bajta 0, tada se sljedećih nekoliko bajtova podataka mora uzeti bez promjene. Koliko je tačno zapisano u preostalih 7 bitova kontrolnog bajta. Na primjer, kontrolni bajt 10000 11 1 2 znači da se sljedeći bajt mora ponoviti 7 puta, a kontrolni bajt 00000100 2 znači da se sljedeća 4 bajta moraju uzeti bez promjena. Dakle, niz je 1000 11 11 2 11 000000 2 00000010 2 11 000001 2 11 000010 2 ponoviti 15 A (šifra 192) 2 B (šifra 193) B (šifra 194) je raspakirano u 17 znakova: AAAAAAAAAAAAAAAABV. RLE algoritam se uspješno koristi za komprimiranje crteža u kojima su velike površine ispunjene istom bojom i nekim audio podacima. Danas se umjesto toga koriste naprednije, ali složenije metode. U nastavku ćemo pogledati jedan od njih (Huffmanovo kodiranje). RLE algoritam se koristi, na primjer, u jednoj od faza kodiranja slika u JPEG formatu. RLE kompresija je takođe dostupna u BMP formatu (za slike sa paletom od 16 ili 256 boja). Najbolji način razumjeti princip rada algoritma - vježbati ga koristiti. Sa autorske web stranice (http://kpolyakov.narod.ru/prog/compress.htm) možete preuzeti besplatni program simulatora, koji je dizajniran za proučavanje RLE algoritma: Na lijevoj strani programa nalazi se uređivač teksta prozor. Kada kliknete na dugme, uneseni tekst se komprimuje pomoću RLE algoritma, kompresovani podaci se prikazuju kao heksadecimalni kodovi na desnoj strani prozora. Prozor sa desne strane je ujedno i uređivač, tako da se kodovi mogu mijenjati i izvršiti obrnuta operacija (raspakivanje, dekompresija) klikom na dugme. Dugmad na vrhu prozora omogućavaju komprimiranje i vraćanje datoteka na disk. Samo trebate uzeti u obzir da program koristi vlastiti format za pohranu podataka. 6. decembar 2012. / INFORMACIJSKA NAUKA Test pitanja 1) Procijenite maksimalni dostižni omjer kompresije koristeći razmatranu verziju RLE algoritma. U kom slučaju će to biti moguće postići? 2) Procijenite omjer kompresije u najgorem slučaju koristeći RLE algoritam. Opišite ovaj najgori scenario. 3) Osmislite tri sekvence koje se ne mogu komprimirati pomoću RLE algoritma. 4) Konstruišite sekvence koje su komprimovane RLE algoritmom tačno 2 puta, 4 puta, 5 puta. Vježba 1) Koristeći RLE algoritam, kodirajte niz znakova BBBBBBACCCABBBBBB Rezultat zapišite kao heksadecimalne kodove (svaki znak je kodiran kao bajt, koji je predstavljen sa dvije heksadecimalne cifre). Provjerite rezultat pomoću RLE programa.
2) Dešifrirajte sekvencu upakovanu korištenjem RLE algoritma (dati su heksadecimalni kodovi): 01 4D 8E 41 01 4D 8E 41 16. Za identifikaciju znakova po njihovim heksadecimalnim kodovima, koristite ASCII tabelu. Odredite broj bajtova u originalnoj i dekomprimiranoj sekvenci i izračunajte omjer kompresije. Provjerite rezultat pomoću RLE programa. Predložite dvije metode provjere. 3) Koristeći RLE program, primijenite RLE kompresiju na sljedeći 1 fajl i pronađite omjer kompresije za svaku od njih. grad_vert.bmp grad_horz.bmp grad_diag.jpg Objasnite dobijene rezultate: zašto su za dvije slike u BMP formatu iste veličine, omjeri kompresije pomoću RLE algoritma toliko različiti; Zašto ne mogu komprimirati slike sačuvane u JPEG formatu? Prefiksni kodovi Razmislite o Morzeovom kodu, koji koristi neujednačen kod za smanjenje dužine poruke - slova koja se često pojavljuju (A, E, M, H, T) su kodirana kratkim nizovima, a rijetka koja se pojavljuju u dužim nizovima. Takav kod se može predstaviti u obliku strukture koja se zove stablo: Root Ovo pokazuje nepotpuno stablo Morzeovog koda, izgrađeno samo za znakove čiji se kodovi sastoje od jednog i dva znaka (tačke i crtice). Stablo se sastoji od čvorova (crna tačka i krugovi sa simbolima abecede) i usmjerenih rubova koji ih povezuju, strelice pokazuju smjer kretanja. Gornji čvor (koji ne uključuje strelice) naziva se “korijen” stabla. Dvije strelice izlaze iz korijena i iz svih međučvorova (osim krajnjih čvorova - „listova“), lijeva je označena tačkom, a desna crticom. Da biste pronašli kod simbola, trebate pratiti strelice od "korijena" stabla do željenog "lista", zapisujući oznake strelica koje pratimo. U stablu nema ciklusa (zatvorenih putanja), tako da se kod za svaki 1 Ove i druge datoteke koje se koriste u zadacima radionice nalaze na dodatnom disku ovom broju časopisa. karakter se određuje na jedinstven način. Koristeći ovo stablo, možete napraviti sljedeće kodove: E I A – T – N – M – – Ovo je neujednačen kod, u kojem znakovi imaju kodove različite dužine. U ovom slučaju, uvijek se javlja problem podjele niza na zasebne kodne riječi. U Morzeovom kodu to se rješava pomoću znaka za razdvajanje - pauze. Međutim, ne morate unijeti dodatni znak ako je Fano uvjet zadovoljen: nijedna kodna riječ nije početak druge kodne riječi. Ovo vam omogućava nedvosmisleno dekodiranje poruke u realnom vremenu kako se primaju sljedeći znakovi. Prefiksni kod je kod u kojem nijedna kodna riječ nije početak druge kodne riječi (Fano uvjet). Robert Fano (r. 1917) (nytimes.com) Claude Shannon (1916–2001) Da bi se ova ideja koristila u kompjuterskoj obradi podataka, bilo je neophodno razviti algoritam za konstruisanje prefiksnog koda. Ovaj problem su prvi, nezavisno jedan od drugog, rešili američki matematičari i inženjeri Claude Shannon (1948.) i Robert Fano (1949.). Koristili su redundantnost poruka, koja se sastoji u tome da znakovi u tekstu imaju različite frekvencije pojavljivanja. U tom slučaju morate dvaput pročitati podatke iz izvorne datoteke: na prvom prolazu se određuje učestalost pojavljivanja svakog znaka, zatim se pravi kod uzimajući u obzir te podatke, a na drugom prolazu tekst znakovi se zamjenjuju njihovim kodovima. Algoritam kodiranja koji su predložili Shannon i Fano nazvan je Shannon-Fano kod. Primjer 3. Neka se tekst sastoji samo od slova O, E, N, T i razmaka. Poznato je koliko puta su se pojavile u tekstu: razmak - 179, O - 89, E - 72, N - 53 i T - 50 puta. Slijedeći Shannon-Fano metodu, dijelimo znakove u dvije grupe tako da je ukupan broj znakova u prvoj grupi koji se nalazi u tekstu približno jednak ukupnom broju znakova u drugoj grupi. U našem slučaju najbolja opcija- ovo je spajanje razmaka i slova T u prvu grupu (zbir 179+50 = 229), a preostalih znakova u drugu (zbir 89+72+53 = 214). Znakovi u prvoj grupi će imati kodove koji počinju sa 0, a ostali - sa 1. U prvoj grupi postoje samo dva znaka, jedan od njih, na primer razmak, imaće drugu cifru koda 0 (i puni kod 00), a drugi će imati 1 (slovni kod T - 01). 7. decembar 2012. / INFORMATIKA
- U kontaktu sa 0
- Google+ 0
- uredu 0
- Facebook 0






