- Instruktaż
Dawno temu, gdy byłem jeszcze naiwnym uczniem, nagle poczułem ogromną ciekawość: w jaki sposób dane w archiwach w magiczny sposób zajmują mniej miejsca? Po zamontowaniu mojego sprawdzonego dialupa zacząłem surfować po Internecie w poszukiwaniu odpowiedzi i znalazłem wiele artykułów z dość szczegółowym przedstawieniem interesujących mnie informacji. Ale żadne z nich nie wydawało się wówczas łatwe do zrozumienia - wykazy kodów przypominały znajomość języka chińskiego, a próby zrozumienia niezwykłej terminologii i różnorodnych formuł nie zakończyły się sukcesem.
Dlatego celem tego artykułu jest przybliżenie najprostszych algorytmów kompresji tym, których wiedza i doświadczenie nie pozwalają jeszcze na natychmiastowe zrozumienie bardziej fachowej literatury, lub których profil jest zupełnie odbiegający od tego typu tematów. Te. Opowiem Ci w skrócie o niektórych najprostszych algorytmach i podam przykłady ich implementacji bez kilometrowych list kodów.
Od razu ostrzegam, że nie będę brał pod uwagę szczegółów realizacji procesu kodowania i takich niuansów jak efektywne wyszukiwanie wystąpień ciągu znaków. Artykuł dotyczyć będzie jedynie samych algorytmów oraz sposobów prezentacji wyników ich pracy.
RLE - zwartość jednorodności
Algorytm RLE jest prawdopodobnie najprostszy ze wszystkich: jego istota polega na kodowaniu powtórzeń. Innymi słowy, bierzemy sekwencje identyczne elementy i „zwiń” je w pary „ilość/wartość”. Na przykład ciąg „AAAAAAAABCCCC” można przekonwertować na ciąg „8×A, B, 4×C”. To w sumie wszystko, co musisz wiedzieć o algorytmie.Przykład wdrożenia
Załóżmy, że mamy zbiór pewnych współczynników całkowitych, które mogą przyjmować wartości od 0 do 255. Logicznie rzecz biorąc, doszliśmy do wniosku, że rozsądne jest przechowywanie tego zestawu jako tablicy bajtów:dane znakowe bez znaku = ( 0, 0, 0, 0, 0, 0, 4, 2, 0, 4, 4, 4, 4, 4, 4, 4, 80, 80, 80, 80, 0, 2, 2 , 2, 2, 255, 255, 255, 255, 255, 0, 0);
Dla wielu znacznie częstsze będzie zobaczenie tych danych w formie zrzutu szesnastkowego:
0000: 00 00 00 00 00 00 04 02 00 04 04 04 04 04 04 04
0010: 50 50 50 50 00 02 02 02 02 FF FF FF FF FF 00 00
Po namyśle uznaliśmy, że dobrze byłoby jakoś skompresować takie zestawy, żeby zaoszczędzić miejsce. W tym celu poddaliśmy je analizie i zidentyfikowaliśmy pewien wzór: bardzo często spotykamy podciągi składające się z identycznych elementów. Oczywiście RLE jest do tego idealny!
Zakodujmy nasze dane wykorzystując nowo zdobytą wiedzę: 6x0, 4, 2, 0, 7x4, 4x80, 0, 4x2, 5x255, 2x0.
Pora w jakiś sposób przedstawić nasz wynik w formie zrozumiałej dla komputera. Aby to zrobić, w strumieniu danych musimy w jakiś sposób oddzielić pojedyncze bajty od zakodowanych ciągów znaków. Ponieważ nasze dane wykorzystują cały zakres wartości bajtów, nie będzie możliwe po prostu wybranie jakichkolwiek zakresów wartości dla naszych celów.
Wyjścia z tej sytuacji są co najmniej dwa:
- Jako wskaźnik skompresowanego łańcucha wybierz wartość jednego bajtu, a w przypadku kolizji z danymi rzeczywistymi wyjdź z niej. Przykładowo, jeśli w celach „oficjalnych” użyjemy wartości 255, to gdy w danych wejściowych napotkamy tę wartość, będziemy zmuszeni wpisać „255, 255” i użyć maksymalnie 254 po wskaźniku.
- Strukturuj zakodowane dane, wskazując ilość nie tylko powtarzających się, ale także kolejnych pojedynczych elementów. Wtedy będziemy z góry wiedzieć, gdzie jakie dane są.
Zatem mamy teraz dwa rodzaje ciągów: łańcuchy pojedynczych elementów (np. „4, 2, 0”) i łańcuchy identycznych elementów (np. „0, 0, 0, 0, 0, 0”). Wybierzmy jeden bit w bajtach „serwisowych” dla typu sekwencji: 0 - elementy pojedyncze, 1 - identyczne. W tym celu weźmy, powiedzmy, najbardziej znaczący fragment bajtu.
W pozostałych 7 bitach będziemy przechowywać długości sekwencji, tj. maksymalna długość zakodowanej sekwencji wynosi 127 bajtów. Moglibyśmy przeznaczyć powiedzmy dwa bajty na potrzeby usług, ale w naszym przypadku tak długie sekwencje są niezwykle rzadkie, więc łatwiej i bardziej ekonomicznie jest po prostu podzielić je na krótsze.
Okazuje się, że najpierw do strumienia wyjściowego zapiszemy długość sekwencji, a następnie albo jedną powtarzalną wartość, albo łańcuch niepowtarzalnych elementów o określonej długości.
Pierwszą rzeczą, która powinna zwrócić Twoją uwagę, jest to, że w tej sytuacji mamy kilka niewykorzystanych wartości. Nie może być sekwencji o zerowej długości, dlatego możemy zwiększyć maksymalną długość do 128 bajtów, odejmując jeden od długości podczas kodowania i dodając jeden podczas dekodowania. W ten sposób możemy zakodować długości od 1 do 128 zamiast długości od 0 do 127.
Drugą rzeczą, którą można zauważyć, jest to, że nie ma ciągów identycznych elementów o jednostkowej długości. Dlatego przy kodowaniu od długości takich sekwencji odejmiemy jeszcze jedną, zwiększając w ten sposób ich maksymalną długość do 129 (maksymalna długość łańcucha pojedynczych elementów to nadal 128). Te. Nasze łańcuchy identycznych elementów mogą mieć długość od 2 do 129.
Zakodujmy nasze dane jeszcze raz, ale teraz w formie zrozumiałej dla komputera. Będziemy pisać bajty serwisowe jako , gdzie T jest typem sekwencji, a L jest długością. Weźmy od razu pod uwagę, że długości zapisujemy w zmodyfikowanej formie: dla T=0 odejmujemy jeden od L, a dla T=1 odejmujemy dwa.
0, , 4, 2, 0, , 4, , 80, , 0, , 2, , 255, , 0
Spróbujmy rozszyfrować nasz wynik:
- . T=1, co oznacza, że kolejny bajt zostanie powtórzony L+2 (4+2) razy: 0, 0, 0, 0, 0, 0.
- . T=0, co oznacza, że po prostu czytamy L+1 (2+1) bajtów: 4, 2, 0.
- . T=1, powtórz kolejny bajt 5+2 razy: 4, 4, 4, 4, 4, 4, 4.
- . T=1, powtórz kolejny bajt 2+2 razy: 80, 80, 80, 80.
- . T=0, odczyt 0+1 bajtów: 0.
- . T=1, powtórz bajt 2+2 razy: 2, 2, 2, 2.
- . T=1, powtórz bajt 3+2 razy: 255, 255, 255, 255, 255.
- . T=1, powtórz bajt 0+2 razy: 0, 0.
A teraz ostatni krok: zapisz wynik jako tablicę bajtów. Na przykład para spakowana w bajt będzie wyglądać następująco:
W efekcie otrzymujemy co następuje:
0000: 84 00 02 04 02 00 85 04 82 80 00 00 82 02 83 FF
0010: 80
00
W ten prosty sposób, korzystając z przykładu danych wejściowych, otrzymaliśmy 18 bajtów z 32 bajtów. Nie jest to zły wynik, szczególnie biorąc pod uwagę, że na dłuższych łańcuchach może się to okazać znacznie lepsze.
Możliwe ulepszenia
Skuteczność algorytmu zależy nie tylko od samego algorytmu, ale także od sposobu jego implementacji. Dlatego dla różnych danych można opracować różne warianty kodowania i reprezentacji zakodowanych danych. Na przykład, kodując obrazy, możesz tworzyć łańcuchy o zmiennej długości: przydziel jeden bit, aby wskazać długi łańcuch, a jeśli jest ustawiony na jeden, zapisz długość również w następnym bajcie. W ten sposób poświęcamy długość krótkich łańcuchów (65 elementów zamiast 129), ale umożliwiamy kodowanie łańcuchów o długości do 16385 elementów (2 14 + 2) za pomocą zaledwie trzech bajtów!Dodatkową wydajność można osiągnąć stosując metody heurystyczne kodowanie. Na przykład, zakodujmy następujący łańcuch naszą metodą: „ABBA”. Otrzymujemy „ , A, , B, , A” - tj. Zamieniliśmy 4 bajty na 6, zawyżając oryginalne dane aż półtora raza! A im więcej takich krótkich, naprzemiennych sekwencji różnych typów, tym więcej jest zbędnych danych. Jeśli weźmiemy to pod uwagę, możemy zakodować wynik jako „, A, B, B, A” - zmarnowalibyśmy tylko jeden dodatkowy bajt.
LZ77 - zwięzłość w powtórzeniach
LZ77 to jeden z najprostszych i najbardziej znanych algorytmów w rodzinie LZ. Nazwany na cześć swoich twórców: Abrahama Lempela L empel) i Jacob Ziv (Jacob Z IV). Cyfry 77 w tytule oznaczają rok 1977, w którym ukazał się artykuł opisujący ten algorytm.Podstawową ideą jest kodowanie identycznych sekwencji elementów. Oznacza to, że jeśli dany łańcuch elementów występuje w danych wejściowych więcej niż jeden raz, wówczas wszystkie jego kolejne wystąpienia można zastąpić „powiązaniami” z jego pierwszą instancją.
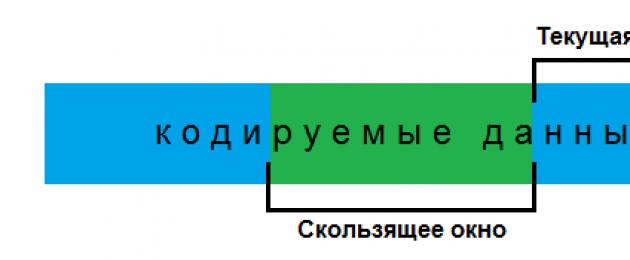
Podobnie jak inne algorytmy z tej rodziny, LZ77 wykorzystuje słownik przechowujący wcześniej napotkane sekwencje. W tym celu stosuje zasadę tzw. „przesuwane okno”: obszar zawsze przed bieżącą pozycją kodowania, w którym możemy adresować odniesienia. Okno to jest słownikiem dynamicznym dla tego algorytmu - każdemu znajdującemu się w nim elementowi odpowiadają dwa atrybuty: pozycja w oknie oraz długość. Chociaż w zmysł fizyczny to tylko fragment pamięci, który już zakodowaliśmy.

Przykład wdrożenia
Spróbujmy teraz coś zakodować. Wygenerujmy do tego odpowiednią linijkę (z góry przepraszam za jej absurdalność):„Kompresja i dekompresja pozostawiają wrażenie. Hahahahaha!”
Tak to będzie wyglądać w pamięci (kodowanie ANSI):
0000: 54 68 65 20 63 6F 6D 70 72 65 73 73 69 6F 6E 20 Kompresja
0010: 61 6E 64 20 74 68 65 20 64 65 63 6F 6D 70 72 65 i dekompresja
0020: 73 73 69 6F 6E 20 6C 65 61 76 65 20 61 6E 20 69 ssion urlop i
0030: 6D 70 72 65 73 73 69 6F 6E 2E 20 48 61 68 61 68 mpresja. Haha
0040: 61 68 61 68 61 21 aha!
Nie zdecydowaliśmy jeszcze o wielkości okna, ale zgodzimy się, że jest ono większe niż rozmiar zakodowanego ciągu znaków. Spróbujmy znaleźć wszystkie powtarzające się ciągi znaków. Łańcuch traktujemy jako sekwencję znaków dłuższą niż jeden. Jeśli łańcuch jest częścią dłuższego, powtarzającego się łańcucha, zignorujemy go.
„Kompresja i t de opuszczają [ an] i . Ha!
Dla większej przejrzystości spójrzmy na diagram, na którym widzimy zgodność pomiędzy powtarzającymi się ciągami a ich pierwszymi wystąpieniami:
Być może jedynym niejasnym punktem będzie tutaj sekwencja „Hahahahaha!”, ponieważ łańcuch znaków „ahahaha” odpowiada krótkiemu łańcuchowi „ah”. Ale nie ma tu nic niezwykłego, zastosowaliśmy pewien trik, dzięki któremu algorytm czasami działa tak, jak opisany wcześniej RLE.
Faktem jest, że podczas rozpakowywania odczytamy określoną liczbę znaków ze słownika. A ponieważ cały ciąg jest okresowy, tj. dane w nim zawarte powtarzają się z pewnym okresem, a symbole pierwszego okresu znajdą się tuż przed pozycją rozpakowania, wówczas z nich możemy odtworzyć cały łańcuch po prostu kopiując symbole poprzedniego okresu do następnego. 
To załatwione. Teraz zamieńmy znalezione powtórzenia na linki do słownika. Link napiszemy w formacie, gdzie P jest pozycją pierwszego wystąpienia łańcucha w linii, L jest jego długością.
„Kompresja i t de opuszczają i. Ha!
Ale nie zapominaj, że mamy do czynienia z oknem przesuwnym. Dla lepszego zrozumienia, aby linki nie były zależne od rozmiaru okna, zamieńmy pozycje bezwzględne na różnicę między nimi a aktualną pozycją kodowania.
„Kompresja i t de opuszczają i. Ha!
Teraz musimy tylko odjąć P od bieżącej pozycji kodowania, aby uzyskać pozycję bezwzględną w ciągu.
Czas zdecydować o wielkości okna i maksymalnej długości zakodowanej frazy. Ponieważ mamy do czynienia z tekstem, rzadko kiedy pojawią się w nim szczególnie długie powtarzające się sekwencje. Przydzielmy więc na ich długość powiedzmy 4 bity – limit 15 znaków na raz nam w zupełności wystarczy.
Jednak wielkość okna decyduje o tym, jak głęboko będziemy szukać identycznych łańcuchów. Ponieważ mamy do czynienia z małymi tekstami, w sam raz będzie uzupełnić liczbę wykorzystywanych przez nas bitów do dwóch bajtów: łącza będziemy adresować w zakresie 4096 bajtów, wykorzystując do tego 12 bitów.
Z doświadczenia z RLE wiemy, że nie wszystkie wartości można zastosować. Oczywiście łącze może mieć minimalną wartość 1, więc aby zaadresować ponownie w zakresie 1..4096, musimy odjąć jeden od łącza podczas kodowania i dodać go z powrotem podczas dekodowania. To samo z długościami sekwencji: zamiast 0..15 użyjemy zakresu 2..17, gdyż nie pracujemy z długościami zerowymi, a poszczególne znaki nie są ciągami.
Przedstawmy zatem nasz zakodowany tekst uwzględniający te poprawki:
„Kompresja i t de opuszczają i. Ha!
Teraz znowu musimy w jakiś sposób oddzielić skompresowane łańcuchy od reszty danych. Najbardziej powszechnym sposobem jest ponowne użycie tej struktury i wyraźne wskazanie, gdzie dane są kompresowane, a gdzie nie. W tym celu podzielimy zakodowane dane na grupy po osiem elementów (symboli lub łączy), a przed każdą z tych grup wstawimy bajt, gdzie każdy bit odpowiada typowi elementu: 0 dla symbolu i 1 dla link.
Dzielimy się na grupy:
- „Komp”
- „resja”
- „i t de”
- "Zostawić"
- "I. Haha”
"(0,0,0,0,0,0,0,0) Reakcja komp(0,0,0,0,0,0,0,0) (0,0,0,0,0,1 ,0,0) i t de(1,0,0,0,0,0,1,0) opuścić (0,1,0,0,0,0,0,1) i . Haha (0)!”
Zatem jeśli podczas rozpakowywania natkniemy się na bit 0, to po prostu wczytujemy znak do strumienia wyjściowego, jeśli bit 1, czytamy link, a z linku czytamy sekwencję ze słownika.
Teraz wszystko, co musimy zrobić, to pogrupować wynik w tablicę bajtów. Ustalmy, że używamy bitów i bajtów w kolejności od najwyższej do najniższej. Zobaczmy, jak linki są pakowane w bajty na przykładzie:
W rezultacie nasz skompresowany strumień będzie wyglądał następująco:
0000: 00 54 68 65 20 63 6f 6d 70 00 72 65 73 73 69 6f #Komp#ressio
0010: 6e 20 04 61 6e 64 20 74 01 31 64 65 82 01 5a 6c n #and t##de###l
0020: 65 61 76 65 01 b1 20 41 69 02 97 2e 20 48 61 68 okap## #i##. Ha
0030: 00 15
00
21 00 00 00 00 00 00 00 00 00 00 00 00
###!
Możliwe ulepszenia
W zasadzie wszystko, co opisano dla RLE, będzie tutaj prawdą. W szczególności, aby zademonstrować użyteczność podejścia heurystycznego podczas kodowania, rozważ następujący przykład:„Długie gouuuu. Dłużej związany.”
Znajdźmy sekwencje tylko dla słowa „loooooower”:
„Długie gouuuu. Najlepiej związane.”
Aby zakodować taki wynik, potrzebujemy czterech bajtów na odwołanie. Jednak bardziej ekonomicznie byłoby to zrobić:
„Długie gouuuu. Byłem związany.
Wtedy wydalibyśmy o jeden bajt mniej.
Zamiast wniosków
Algorytmy te, pomimo swojej prostoty i pozornie mało skutecznej, są nadal szeroko stosowane w różnych obszarach sektora IT.Ich zaletą jest prostota i szybkość, a na ich zasadach i ich kombinacjach można budować bardziej złożone i efektywne algorytmy.
Mam nadzieję, że przedstawiona w ten sposób istota tych algorytmów pomoże komuś zrozumieć podstawy i zacząć patrzeć w stronę poważniejszych rzeczy.
Kodowanie długości przebiegu (RLE) lub kodowanie powtarzalne to prosty algorytm kompresji danych, który działa na seriach danych, czyli sekwencjach, w których ten sam znak pojawia się kilka razy z rzędu. Podczas kodowania ciąg identycznych znaków tworzących serię jest zastępowany ciągiem zawierającym sam powtarzający się znak i liczbę jego powtórzeń.
Charakterystyka algorytmu RLE:
Współczynniki kompresji: Pierwsza opcja: 32, 2, 0,5. Opcja druga: 64, 3, 128/129. (Najlepszy, średni, najgorszy kurs). Klasa obrazu: Algorytm koncentruje się na obrazach o małej liczbie kolorów: grafice biznesowej i naukowej. Symetria: O jednym.
Charakterystyka: DO pozytywne aspekty Jedyne, co można przypisać algorytmowi, to to, że nie wymaga dodatkowej pamięci podczas archiwizacji i rozpakowywania, a także działa szybko. Ciekawa funkcja kodowanie grupowe polega na tym, że stopień archiwizacji niektórych obrazów można znacznie zwiększyć, po prostu zmieniając kolejność kolorów w palecie obrazów.
Pierwsza wersja algorytmu
Algorytm ten jest niezwykle prosty w implementacji. Kodowanie grupowe – z angielskiego Runlength Encoding (RLE) – to jeden z najstarszych i najprostszych algorytmów archiwizacji grafiki. Znajdujący się w nim obraz (podobnie jak w kilku algorytmach opisanych poniżej) jest wciągany w łańcuch bajtów wzdłuż linii rastrowych. Sama kompresja w RLE następuje dlatego, że oryginalny obraz istnieją łańcuchy identycznych bajtów. Zastępując je parami<licznik powtórzeń, wartość> zmniejsza redundancję danych.
Algorytm przeznaczony jest do grafiki biznesowej – obrazów o dużych obszarach powtarzających się kolorów. Sytuacja, gdy plik się rozrasta, nie jest tak rzadka w przypadku tego prostego algorytmu. Można to łatwo uzyskać, stosując kodowanie grupowe do przetworzonych kolorowych fotografii. Aby podwoić obraz, należy zastosować go do obrazu, w którym wartości wszystkich pikseli są większe niż binarne 11000000 i nie powtarzają się parami z rzędu.
Druga wersja algorytmu
Druga wersja tego algorytmu ma większy maksymalny współczynnik archiwizacji i w mniejszym stopniu zwiększa rozmiar oryginalnego pliku.
29. Algorytm kompresji lzw
Algorytm został nazwany od pierwszych liter nazwisk jego twórców - Lempel, Ziv I Welcha.
Algorytm LZW opiera się na idei rozszerzania alfabetu, co pozwala na użycie dodatkowych znaków do reprezentowania ciągów znaków regularnych. Używając np. 9-bitowych kodów ASCII zamiast 8-bitowych, otrzymujesz dodatkowe 256 znaków. Praca kompresora sprowadza się do zbudowania tabeli składającej się z wierszy i odpowiadających im kodów. Algorytm kompresji sprowadza się do tego, że program wczytuje kolejny znak i dodaje go do ciągu. Jeśli wiersz znajduje się już w tabeli, czytanie jest kontynuowane, jeśli nie, dana linia jest dodawany do tabeli ciągów. Im więcej jest zduplikowanych linii, tym bardziej dane zostaną skompresowane. Wracając do przykładu z telefonem, możemy posługując się bardzo uproszczoną analogią powiedzieć, że kompresując rekord 233 34 44 metodą LZW, skończymy na wprowadzeniu nowych linii - 333 i 444 i wyrażeniu ich dodatkowymi znakami, będziemy mogli zmniejszyć długość rekordu.
Charakterystyka algorytmu LZW:Współczynniki kompresji: Około 1000, 4, 5/7 (najlepszy, średni, najgorszy kurs). Kompresję 1000 razy osiąga się tylko w przypadku obrazów jednokolorowych, których rozmiar jest wielokrotnością około 7 MB. Klasa obrazu: LZW koncentruje się na obrazach 8-bitowych zbudowanych na komputerze. Kompresuje ze względu na identyczne podłańcuchy w strumieniu. Symetria: Prawie symetryczny, pod warunkiem, że operacja wyszukiwania wiersza w tabeli jest optymalnie zaimplementowana.
Charakterystyka: Sytuacja, w której algorytm powiększa obraz, jest niezwykle rzadka. LZW jest uniwersalny – to właśnie jego odmiany stosowane są w konwencjonalnych archiwizatorach.
Proces kompresji wygląda dość prosto. Odczytujemy sekwencyjnie znaki strumienia wejściowego i sprawdzamy, czy taki ciąg istnieje w utworzonej przez nas tabeli ciągów. Jeśli jest linia to czytamy kolejny znak, a jeśli nie ma linii to do strumienia wpisujemy kod poprzednio znalezionej linii, wpisujemy linię do tabeli i rozpoczynamy wyszukiwanie od nowa.
Osobliwością LZW jest to, że do dekompresji nie ma potrzeby zapisywania tabeli ciągów znaków w pliku do dekompresji. Algorytm został zaprojektowany w taki sposób, że jesteśmy w stanie odtworzyć tablicę ciągów wykorzystując jedynie strumień kodów.
Przygotowanie dokumentu
i użyj tego stylu, aby sformatować formułę wpisaną w formacie LaT E X.
Zaprojektuj nagłówek „Literatura” w stylu „ Nagłówek 2" Podaj informacje o książce D. Knutha w formie listy numerowanej.
Znajdź informacje o książce „Everything about T E X” na stronie wydawnictwa Williams i w tytule książki umieść hiperłącze do znalezionej strony. Sprawdź, czy hiperłącze działa.
Algorytm RLE
Używając algorytmu RLE, zakoduj ciąg znaków
Zapisz wynik w postaci kodów szesnastkowych (każdy znak jest kodowany jako bajt reprezentowany przez dwie cyfry szesnastkowe). Sprawdź wynik za pomocą programu RLE.
Odkoduj sekwencję spakowaną algorytmem RLE (podano kody szesnastkowe): 01 4D 8E 41 01 4D 8E 41 16 . Aby identyfikować znaki na podstawie ich kodu szesnastkowego, użyj tabeli ASCII. Określ liczbę bajtów w oryginalnej i rozpakowanej sekwencji i oblicz współczynnik kompresji:
Wynik uzyskany w poprzednim akapicie sprawdź za pomocą programu RLE. Zaproponuj dwie metody weryfikacji.
Konstruuj sekwencje skompresowane przez algorytm RLE dokładnie 2 razy, 4 razy, 5 razy. Sprawdź swoje odpowiedzi korzystając z programu RLE.
Nieskompresowana sekwencja
Skompresowana sekwencja
Stopień sprężania
2
4
5
Pomyśl o trzech sekwencjach, których nie można skompresować za pomocą algorytmu RLE:
Nieskompresowana sekwencja
Sekwencja „skompresowana”.
Stopień sprężania
Za pomocą programu RLE zastosuj kompresję RLE do następujących plików i znajdź współczynnik kompresji dla każdego z nich:
Plik
Rozmiar nieskompresowany
Rozmiar po kompresji
Stopień sprężania
grad_vert.bmp
grad_horz.bmp
grad_diag.jpg
Wyjaśnij wyniki uzyskane w poprzednim akapicie:
Dlaczego kompresowanie zdjęć w formacie JPEG nie jest korzystne?
Dlaczego współczynniki kompresji RLE są tak różne dla dwóch obrazów BMP o tym samym rozmiarze? Wskazówka: Otwórz te zdjęcia w dowolnej przeglądarce.
Oszacuj maksymalny osiągalny stopień kompresji, korzystając z wersji algorytmu RLE omówionej w podręczniku. W jakim przypadku uda się to osiągnąć?
Oszacuj współczynnik kompresji w najgorszym przypadku, korzystając z algorytmu RLE. Opisz ten najgorszy scenariusz.
Porównanie algorytmów kompresji
Uruchom program Huffman.exe i zakoduj ciąg „RACOON DOESN'T DROWN”, używając metod Shannona-Fano i Huffmana. Zapisz wyniki w tabeli:
| Shannon i Fano | Huffmana |
|
| Główna długość kodu | ||
| | ||
| | ||
| |
Wyciągać wnioski.
Odpowiedź:
Jak Twoim zdaniem zmieni się współczynnik kompresji wraz ze wzrostem długości tekstu, pod warunkiem, że zestaw znaków i ich częstotliwość pozostaną niezmienione? Sprawdź wynik za pomocą programu (na przykład możesz skopiować tę samą frazę kilka razy).
Odpowiedź:
Powtórz eksperyment ze zwrotem „NOWY SZOP”.
| Shannon i Fano | Huffmana |
|
| Główna długość kodu | ||
| Długość tabeli kodów (drzewa) | ||
| Współczynnik kompresji (według głównych kodów) | ||
| Współczynnik kompresji (z uwzględnieniem drzewa kodowego) |
Wyciągać wnioski.
Odpowiedź:
Narysuj w swoim notatniku drzewa kodu utworzone przez program przy użyciu obu metod.
Korzystanie z przycisku Analiza plików w programie Huffmana a.txt 1 z kodowaniem bajtowo-bajtowym.
Korzystanie z programów RLE I Huffmana skompresuj plik A. tekst różne sposoby. Zapisz wyniki w tabeli:
Wyjaśnij wynik uzyskany przy użyciu algorytmu RLE.
Odpowiedź:
Korzystanie z przycisku Analiza plików w programie Huffmana, określ maksymalny teoretyczny współczynnik kompresji pliku a.txt.huf z kodowaniem bajtowo-bajtowym. Wyjaśnij wynik.
Ponownie skompresuj ten plik, używając algorytmu Huffmana kilka razy (nowe pliki zostaną nazwane a.txt.huf2, a.txt.huf3 itp.) i wypełniamy tabelę, każdorazowo analizując powstały plik.
| rozmiar pliku | |
|
| a.txt | ||
| a.txt.huf | ||
| a.txt.huf2 | ||
| a.txt.huf3 | ||
| a.txt.huf4 | ||
| a.txt.huf5 |
Odpowiedź:
Wykonaj te same kroki, stosując metodę Shannona-Fano.
| rozmiar pliku | Ogranicz stopień kompresji |
|
| a.txt | ||
| a.txt.shf | ||
| a.txt.shf2 | ||
| a.txt.shf3 | ||
| a.txt.shf4 | ||
| a.txt.shf5 |
Wyjaśnij, dlaczego po pewnym momencie, gdy plik jest ponownie kompresowany, jego rozmiar wzrasta.
Odpowiedź:
Porównaj wyniki kompresji tego pliku algorytmem RLE, najlepsze wyniki uzyskane metodami Shannona-Fano i Huffmana, a także wynik kompresji tego pliku jakimś archiwizatorem.
| rozmiar pliku | Ogranicz stopień kompresji |
|
| RLE | ||
| Huffmana | ||
| Shannon i Fano | ||
| zamek błyskawiczny | ||
| RAR | ||
| 7Z |
Wyjaśnij wyniki i wyciągnij wnioski.
Odpowiedź:
Korzystanie z archiwizatora
Poznaj możliwości archiwizatora zainstalowanego na Twoim komputerze ( Arka, 7- Zamek błyskawiczny, WinRARA lub inne).
Otwórz katalog wskazany przez nauczyciela. Powinien zawierać wszystkie pliki, które będą dalej wykorzystywane.
Rozpakuj archiwum sekret.zamek błyskawiczny który jest wypełniony hasłem sekret łac. W powstałych podkatalogach po rozpakowaniu powinieneś znaleźć 3 pliki zawierające fragmenty łacińskiego powiedzenia, które oznacza „umowy należy dotrzymywać”.
Utwórz nowy plik tekstowy latin.txt i zapisz to zdanie po łacinie. Następnie usuń archiwum sekret.zip.
Skompresuj każdy plik wymieniony w tabeli osobno, korzystając z formatu archiwum określonego przez nauczyciela. Oblicz współczynnik kompresji (wygodnie jest w tym celu skorzystać z arkusza kalkulacyjnego):
| Nazwa pliku | Opis | Głośność do kompresja, KB | Objętość po kompresji, KB | Stopień sprężania |
| losowe.dat | losowe dane | 391 | ||
| poranek.zip | skompresowany plik | 244 | ||
| zachód słońca.jpg | rysunek w formacie JPEG | 730 | ||
| prog.exe | program dla Okna | 163 | ||
| sygnał.mp3 | Dźwięk MP3 | 137 | ||
| las.wav | dźwięk w formacie WAV | 609 | ||
| ładoga.bmp | rysunek w formacie BMP | 9217 | ||
| tołstoj.txt | tekst | 5379 |
Zapisz w swoim notatniku swoje ustalenia dotyczące tego, które pliki zazwyczaj kompresują się lepiej, a które gorzej.
Jeśli Twój archiwizator umożliwia tworzenie samorozpakowujących się archiwów, porównaj rozmiary zwykłego archiwum i archiwum SFX dla pliku tłuszczowy. tekst:
Wyjaśnij, dlaczego rozmiary obu archiwów są różne. Następnie usuń oba utworzone archiwa.
Przenieś zdjęcia do osobnego katalogu Kino, a pliki dźwiękowe - do katalogu Dźwięki.
Pakuj obrazy i dźwięki w archiwum Głoska bezdźwięczna z hasłem media123.
Spakuj wszystkie pozostałe pliki i foldery do archiwum Dane(bez hasła).
Usuń wszystkie pliki z wyjątkiem archiwów Głoska bezdźwięczna I Dane, i pokaż swoją pracę nauczycielowi.
Kompresja stratna
Skopiuj plik do swojego folderu valaam.jpg.
Korzystanie z edytora grafiki rastrowej ( KORDONEK, Photoshopa), zapisz kilka kopii tego rysunku o różnej jakości, od 0% do 100%.
| Jakość, % | 0 | 10 | 20 | 30 | 40 | 50 | 60 | 70 | 80 | 90 | 100 |
| Rozmiar pliku, KB |
Korzystając z edytora arkuszy kalkulacyjnych, utwórz wykres wykorzystując te dane. Wyciągać wnioski.
Przeglądaj pliki uzyskane przy różnych poziomach kompresji. Wybierz opcję, która Twoim zdaniem jest najlepsza, gdy jakość obrazu pozostaje akceptowalna pomimo małego rozmiaru pliku.
Skopiuj plik dźwiękowy do swojego folderu niedźwiedzie. poseł3 .
Korzystanie z edytora dźwięku (np. Śmiałość), zapisz wiele kopii tego pliku audio o różnej jakości. Dla formatu OggVorbisa dla formatu użyj jakości od 0% do 100%. MP3– bitrate od 16 do 128 Kbps.
Wypełnij tabelę w edytorze arkuszy kalkulacyjnych
Zbuduj wykres wykorzystując te dane. Wyjaśnij, dlaczego wystąpiła ta konkretna relacja.
Słuchaj plików uzyskanych na różnych poziomach kompresji. Wybierz opcję, która Twoim zdaniem jest najlepsza, jeśli rozmiar pliku utrzymuje akceptowalną jakość dźwięku.
Pierwsza wersja algorytmu
Algorytm ten jest niezwykle prosty w implementacji. Kodowanie grupowe – z angielskiego Runlength Encoding (RLE) – to jeden z najstarszych i najprostszych algorytmów archiwizacji grafiki. Znajdujący się w nim obraz (podobnie jak w kilku algorytmach opisanych poniżej) jest wciągany w łańcuch bajtów wzdłuż linii rastrowych. Następuje sama kompresja w RLE ze względu na fakt, że obraz źródłowy zawiera łańcuchy identycznych bajtów. Zastępując je parami<счетчик повторений, значение>zmniejsza redundancję danych.
Algorytm dekompresja To wygląda tak:
Inicjalizacja(...);
Do (
if(jest licznikiem(bajtem)) (
licznik = Low6bits(bajt)+1;
for(i=1 do licznika)
De
}
w przeciwnym razie(
DecompressedFile.WriteByte(bajt)
) podczas(ImageFile.EOF());
W tym algorytmie znakiem licznika są te znajdujące się w dwóch górnych bitach czytanego pliku:
Odpowiednio pozostałe 6 bitów wydaje się na licznik, który może przyjmować wartości od 1 do 64. Zamieniamy ciąg 64 powtarzających się bajtów na dwa bajty, tj. Skompresujmy to 32 razy.
Ćwiczenia: Utwórz algorytm kompresja dla pierwszej wersji algorytmu RLE.
Algorytm przeznaczony jest do grafiki biznesowej – obrazów o dużych obszarach powtarzających się kolorów. Sytuacja, gdy plik się rozrasta, nie jest tak rzadka w przypadku tego prostego algorytmu. Można to łatwo uzyskać, stosując kodowanie grupowe do przetworzonych kolorowych fotografii. Aby podwoić obraz, należy zastosować go do obrazu, w którym wartości wszystkich pikseli są większe niż binarne 11000000 i nie powtarzają się parami z rzędu.Pytanie do samokontroli: Podaj dwa lub trzy przykłady „złych” obrazów dla algorytmu RLE. Wyjaśnij, dlaczego skompresowany plik jest większy niż plik oryginalny.
Algorytm ten jest zaimplementowany w formacie PCX. Zobacz na przykład załącznik.Druga wersja algorytmu
Druga wersja tego algorytmu ma większy maksymalny współczynnik archiwizacji i w mniejszym stopniu zwiększa rozmiar oryginalnego pliku.
Algorytm dekompresji wygląda następująco:
Inicjalizacja(...);
Do (
bajt = ImageFile.ReadNextByte();
licznik = Low7bits(bajt)+1;
if(if powtórz flagę(bajt)) (
wartość = ImageFile.ReadNextByte();
dla (i=1 do licznika)
CompressedFile.WriteByte(wartość)
}
w przeciwnym razie(
for(i=1 do licznika)(
wartość = ImageFile.ReadNextByte();
CompressedFile.WriteByte(wartość)
}
CompressedFile.WriteByte(bajt)
) podczas(ImageFile.EOF());
Znakiem powtórzenia w tym algorytmie jest jeden w najbardziej znaczącym bicie odpowiedniego bajtu:

Jak łatwo obliczyć, w najlepszym przypadku algorytm ten kompresuje plik 64 razy (a nie 32 razy jak w poprzedniej wersji), w najgorszym przypadku zwiększa go o 1/128. Średni stopień kompresji tego algorytmu kształtuje się na poziomie pierwszej opcji.
Ćwiczenia: Utwórz algorytm kompresji dla drugiej wersji algorytmu RLE.
Podobne schematy kompresji są używane jako jeden z obsługiwanych algorytmów formacie TIFF, a także w formacie TGA.Charakterystyka algorytmu RLE:
Współczynniki kompresji: Pierwsza opcja: 32, 2, 0,5. Opcja druga: 64, 3, 128/129.(Najlepszy, średni, najgorszy kurs)
Klasa obrazu: Algorytm skupia się na obrazach o małej liczbie kolorów: grafice biznesowej i naukowej.
Symetria: Około jeden.
Cechy charakterystyczne: Być może jedyną pozytywną stroną algorytmu jest to, że nie wymaga on dodatkowej pamięci podczas archiwizacji i rozpakowywania, a także działa szybko. Ciekawą cechą kodowania wsadowego jest to, że stopień archiwizacji niektórych obrazów można znacznie zwiększyć, po prostu zmieniając kolejność kolorów w palecie obrazów.
Algorytm LZWAlgorytm został nazwany od pierwszych liter nazwisk jego twórców – Lempela, Ziva i Welcha. Kompresja w nim, w przeciwieństwie do RLE, odbywa się przy użyciu identycznych łańcuchów bajtów.
Algorytm LZ
Istnieje dość duża rodzina algorytmów typu LZ, różniących się między innymi sposobem wyszukiwania powtarzających się łańcuchów. Jeden z wystarczających proste opcje Algorytm ten zakłada na przykład, że strumień wejściowy zawiera parę<счетчик, смещение относительно текущей позиции>, Lub tylko<счетчик>„pominięte” bajty i same wartości bajtów (jak w drugiej wersji algorytmu RLE). Podczas rozpakowywania dla pary<счетчик, смещение>skopiowane<счетчик>bajt z tablicy wyjściowej uzyskanej w wyniku rozpakowania, do<смещение>bajt wcześniej<счетчик>(tj. liczba równa licznikowi) wartości bajtów „pominięcia” są po prostu kopiowane do tablicy wyjściowej ze strumienia wejściowego. Algorytm ten jest asymetryczny w czasie, ponieważ przy poszukiwaniu identycznych podciągów wymaga pełnego przeszukania bufora. W rezultacie trudno nam określić duży bufor ze względu na gwałtowny wzrost czasu kompresji. Jednak potencjalnie zbudowanie algorytmu, w którym<счетчик>i dalej<смещение>Przydzielone zostaną 2 bajty (najbardziej znaczący bit starszego bajtu licznika jest oznaką powtarzania linii/kopiowania strumienia), co daje nam możliwość skompresowania wszystkich powtarzających się podciągów do rozmiaru 32 Kb w buforze 64 Kb.
W tym przypadku otrzymamy zwiększenie rozmiaru pliku w najgorszym przypadku o 32770/32768 (w dwóch bajtach jest napisane, że kolejne 2 15 bajtów trzeba przepisać do strumienia wyjściowego), co wcale nie jest złe . Maksymalny stopień kompresji wyniesie 8192 razy. W limicie, ponieważ maksymalną kompresję osiągamy zamieniając bufor 32Kb na 4 bajty, a bufora tej wielkości nie będziemy od razu gromadzić. Jednak minimalny podciąg, dla którego korzystne jest dla nas wykonanie kompresji, powinien na ogół składać się z co najmniej 5 bajtów, co stanowi o niskiej wartości tego algorytmu. Do zalet LZ zalicza się ekstremalna prostota algorytmu dekompresji.
Ćwiczenia: Zaproponuj inną wersję algorytmu LZ, w której dla pary<счетчик, смещение>Zostaną przydzielone 3 bajty i obliczone zostaną główne cechy algorytmu.
Algorytm LZWWariant algorytmu, który rozważamy poniżej, będzie wykorzystywał drzewo do reprezentowania i przechowywania łańcuchów. Oczywiście jest to dość mocne ograniczenie rodzaju łańcuchów i nie wszystkie identyczne podłańcuchy na naszym obrazie zostaną wykorzystane podczas kompresji. Jednakże w proponowanym algorytmie korzystna jest kompresja nawet łańcuchów składających się z 2 bajtów.
Proces kompresji wygląda dość prosto. Odczytujemy sekwencyjnie znaki strumienia wejściowego i sprawdzamy, czy taki ciąg istnieje w utworzonej przez nas tabeli ciągów. Jeśli jest linia to czytamy kolejny znak, a jeśli nie ma linii to do strumienia wpisujemy kod poprzednio znalezionej linii, wpisujemy linię do tabeli i rozpoczynamy wyszukiwanie od nowa.
Funkcja InitTable() czyści tabelę i umieszcza w niej wszystkie wiersze o długości jednostkowej.
Tabela inicjująca();
CompressedFile.WriteCode(ClearCode);
CurStr=pusty ciąg;
while(not ImageFile.EOF())( //Do końca pliku
C=ImageFile.ReadNextByte();
if(CurStr+C jest w tabeli)
CurStr=CurStr+C;//Przyklej znak do ciągu
w przeciwnym razie(
code=CodeForString(CurStr);//kod nie jest bajtem!
AddStringToTable(CurStr+C);
CurStr=C; // Ciąg jednego znaku
}
}
kod=KodForString(CurStr);
CompressedFile.WriteCode(kod);
CompressedFile.WriteCode(CodeEndOfInformation);
Jak omówiono powyżej, funkcja InitTable() inicjuje tabelę ciągów tak, aby zawierała wszystkie możliwe ciągi jednoznakowe. Przykładowo, jeśli skompresujemy dane bajtowe, wówczas w tabeli będzie 256 takich wierszy („0”, „1”,…, „255”). Dla ClearCode i końca kodu informacyjnego (CodeEndOfInformation) zarezerwowane są wartości 256 i 257. W rozważanej wersji algorytmu używany jest kod 12-bitowy i odpowiednio dla kodów linii pozostajemy. o wartościach od 258 do 4095. Dodane wiersze są zapisywane do tabeli sekwencyjnie, przy czym indeks wiersza w tabeli staje się jego kodem.
Funkcja ReadNextByte() odczytuje znak z pliku. Funkcja WriteCode() zapisuje kod (rozmiar nierówny bajtowi) do pliku wyjściowego. Funkcja AddStringToTable() dodaje nowy wiersz do tabeli poprzez przypisanie do niego kodu. Dodatkowo ta funkcja radzi sobie z sytuacjami przepełnienia tabeli. W tym przypadku do strumienia zapisywany jest kod znalezionego poprzednio wiersza oraz kod kasujący, po czym tabela jest czyszczona przez funkcję InitTable(). Funkcja CodeForString() znajduje ciąg znaków w tabeli i drukuje kod tego ciągu.
Przykład:
Skompresujmy sekwencję 45, 55, 55, 151, 55, 55, 55. Następnie zgodnie z algorytmem opisanym powyżej, najpierw umieścimy kod czyszczący w strumieniu wyjściowym<256>, następnie dodaj „45” do początkowo pustej linii i sprawdź, czy w tabeli znajduje się linia „45”. Ponieważ podczas inicjalizacji wpisaliśmy do tabeli wszystkie linie jednego znaku, w tabeli znajduje się linia „45”. Następnie ze strumienia wejściowego odczytujemy kolejny znak 55 i sprawdzamy, czy w tabeli znajduje się ciąg „45, 55”. Nie ma jeszcze takiego wiersza w tabeli. Do tabeli wpisujemy wiersz „45, 55” (z pierwszym wolnym kodem 258) i zapisujemy kod do strumienia<45>. Możesz krótko wyobrazić sobie taką archiwizację:
- „45” - znajduje się w tabeli;
- „45, 55” – nie. Dodaj do tabeli<258>„45, 55”. Aby przesyłać strumieniowo:<45>;
- „55, 55” – nie. Na stół:<259>„55, 55”. Aby przesyłać strumieniowo:<55>;
- „55, 151” – nr. Na stół:<260>„55, 151.” Aby przesyłać strumieniowo:<55>;
- „151, 55” – nr. Na stół:<261>„151, 55.” Aby przesyłać strumieniowo:<151>;
- „55, 55” - znajduje się w tabeli;
- „55, 55, 55” – nie. Do stołu: „55, 55, 55”<262>. Aby przesyłać strumieniowo:<259>;
Osobliwością LZW jest to, że do dekompresji nie musimy zapisywać tabeli ciągów do pliku w celu dekompresji. Algorytm został zaprojektowany w taki sposób, że jesteśmy w stanie odtworzyć tablicę ciągów wykorzystując jedynie strumień kodów.
Wiemy, że dla każdego kodu musimy dodać do tabeli linię składającą się z linii już tam występującej oraz znaku, od którego zaczyna się kolejna linia w strumieniu.

Algorytm dekompresji przeprowadzający tę operację jest następujący:
kod=Plik.OdczytKod();
while(kod != CodeEndOfInformation)(
if(kod = ClearCode) (
Tabela inicjująca();
kod=Plik.OdczytKod();
if(code = CodeEndOfInformation)
(kończyć pracę);
ImageFile.WriteString(StrFromTable(kod));
stary_kod=kod;
}
w przeciwnym razie(
if(InTable(kod)) (
ImageFile.WriteString(FromTable(kod));
AddStringToTable(StrFromTable(stary_kod)+
FirstChar(StrFromTable(kod)));
stary_kod=kod;
}
w przeciwnym razie(
OutString= StrFromTable(stary_kod)+
FirstChar(StrFromTable(old_code));
ImageFile.WriteString(OutString);
AddStringToTable(OutString);
stary_kod=kod;
}
}
}
Tutaj funkcja ReadCode() odczytuje następny kod z zdekompresowanego pliku. Funkcja InitTable() wykonuje te same czynności, co podczas kompresji, tj. czyści tabelę i zapisuje do niej wszystkie wiersze tego samego znaku. Funkcja FirstChar() zwraca nam pierwszy znak ciągu. Funkcja StrFromTable() zwraca wiersz z tabeli za pomocą kodu. Funkcja AddStringToTable() dodaje nowy wiersz do tabeli (podając jej pierwszy wolny kod). Funkcja WriteString() zapisuje ciąg znaków do pliku.
Notatka 1. Jak zapewne zauważyłeś, liczba kodów zapisywanych w strumieniu stopniowo rośnie. Dopóki np. po raz pierwszy w tabeli nie pojawi się kod 512, wszystkie kody będą mniejsze niż 512. Dodatkowo podczas kompresji i dekompresji kody w tabeli dodawane są podczas przetwarzania tego samego znaku, tj. dzieje się to „synchronicznie”. Możemy wykorzystać tę właściwość algorytmu, aby zwiększyć stopień kompresji. Dopóki do tablicy nie zostanie dodany 512 znak, do wyjściowego strumienia bitów będziemy pisać kody 9-bitowe, a zaraz po dodaniu 512 - kody 10-bitowe. Odpowiednio, dekompresor będzie musiał także postrzegać wszystkie kody strumienia wejściowego jako 9-bitowe, dopóki kod 512 nie zostanie dodany do tablicy, po czym będzie postrzegał wszystkie kody wejściowe jako 10-bitowe. To samo zrobimy dodając do tabeli kody 1024 i 2048. Ta technika pozwala nam zwiększyć stopień kompresji o około 15%:

Uwaga 2. Podczas kompresji obrazu ważne jest dla nas zapewnienie szybkości wyszukiwania wierszy w tabeli. Możemy skorzystać z faktu, że każdy kolejny podciąg jest o jeden znak dłuższy od poprzedniego, dodatkowo poprzednią linię znaleźliśmy już w tabeli. Wystarczy zatem utworzyć listę odniesień do wierszy rozpoczynających się od danego podciągu, a cały proces wyszukiwania w tabeli zostanie zredukowany do przeszukiwania wierszy zawartych na liście dla poprzedniego wiersza. Oczywiste jest, że taką operację można przeprowadzić bardzo szybko.
Zauważ też, że w rzeczywistości wystarczy nam przechowywanie w tabeli tylko pary<код предыдущей подстроки, добавленный символ>. Ta informacja wystarczy, aby algorytm zadziałał. Zatem tablica od 0 do 4095 z elementami<код предыдущей подстроки; добавленный символ; список ссылок на строки, начинающиеся с этой строки>rozwiązuje zadany problem wyszukiwania, chociaż bardzo powoli.
W praktyce do przechowywania tabeli wykorzystuje się rozwiązanie typu hash table, które jest tak samo szybkie jak w przypadku list, ale bardziej zwarte w pamięci. Tabela składa się z 8192 (2 13) elementów. Każdy element zawiera<код предыдущей подстроки; добавленный символ; код этой строки>. 20-bitowy klucz wyszukiwania tworzony jest przy użyciu pierwszych dwóch elementów przechowywanych w tabeli jako pojedyncza liczba (klucz). Dolne 12 bitów tej liczby jest przypisanych do kodu, a kolejne 8 bitów do wartości symbolu.
Poniższa funkcja jest używana jako funkcja skrótu:
Indeks (klawisz) = ((klawisz >> 12) ^ klawisz) & 8191;
Gdzie >> to bitowe przesunięcie w prawo (klawisz >> 12 - otrzymujemy wartość znaku), ^ to logiczna bitowa operacja wykluczająca LUB, & to logiczne bitowe AND.
Tym samym w kilku porównaniach otrzymujemy wymagany kod lub komunikat, że takiego kodu nie ma w tabeli.
Obliczmy najlepszy i najgorszy współczynnik kompresji dla tego algorytmu. Najlepszy współczynnik uzyskamy oczywiście dla długiego łańcucha identycznych bajtów (czyli dla obrazu 8-bitowego, którego wszystkie piksele mają z całą pewnością kolor 0). W tym przypadku w 258 wierszu tabeli napiszemy ciąg „0, 0”, w 259 - „0, 0, 0”, ... w 4095 - ciąg 3839 (=4095-256) zer . W tym przypadku strumień będzie zawierał (sprawdź algorytm!) 3840 kodów, łącznie z kodem rozliczeniowym. Dlatego też obliczając sumę postępu arytmetycznego od 2 do 3839 (czyli długość skompresowanego łańcucha) i dzieląc ją przez 3840*12/8 (do strumienia zapisywane są kody 12-bitowe), otrzymamy najlepszą kompresję stosunek.
Ćwiczenia: Oblicz dokładną wartość najlepszego współczynnika kompresji. Trudniejsze zadanie: obliczyć ten sam współczynnik, biorąc pod uwagę uwagę 1.
Najgorszy współczynnik otrzymamy, jeśli nigdy nie natrafimy na podciąg, który już znajduje się w tabeli (nie powinno w nim być ani jednej identycznej pary znaków).Ćwiczenia: Utwórz algorytm generowania takich łańcuchów. Spróbuj skompresować powstały plik przy użyciu standardowych archiwizatorów (zip, arj, gz). Jeśli otrzymasz kompresję, algorytm generowania jest napisany niepoprawnie.
Jeśli stale napotykamy nowy podciąg, zapiszemy w strumieniu wyjściowym 3840 kodów, co będzie odpowiadać ciągowi 3838 znaków. Bez uwzględnienia uwagi 1 będzie to wzrost pliku prawie 1,5-krotny.LZW jest realizowany w formatach GIF i TIFF.
Charakterystyka algorytmu LZW:
Współczynniki kompresji: około 1000, 4, 5/7 (najlepszy, średni, najgorszy współczynnik). Kompresję 1000 razy osiąga się tylko w przypadku obrazów jednokolorowych, których rozmiar jest wielokrotnością około 7 MB.
Klasa obrazu: LZW koncentruje się na obrazach 8-bitowych zbudowanych na komputerze. Kompresuje ze względu na identyczne podłańcuchy w strumieniu.
Symetria: Prawie symetryczny, pod warunkiem, że operacja wyszukiwania wiersza w tabeli zostanie optymalnie zaimplementowana.
Charakterystyka: Sytuacja, w której algorytm powiększa obraz, zdarza się niezwykle rzadko. LZW jest uniwersalny – to właśnie jego odmiany stosowane są w konwencjonalnych archiwizatorach.
Algorytm HuffmanaKlasyczny algorytm Huffmana
Jeden z klasycznych algorytmów znanych od lat 60-tych. Używa tylko częstotliwości występowania identycznych bajtów w obrazie. Przypisuje znaki strumienia wejściowego, które występują więcej razy, do ciągu bitów o krótszej długości. I wręcz przeciwnie, rzadkie - łańcuch o większej długości. Aby zebrać statystyki, wymagane są dwa przejścia nad obrazem.
Na początek wprowadźmy kilka definicji.
Definicja. Niech alfabet Y =( A 1, ..., r ), składający się ze skończonej liczby liter. Skończona sekwencja znaków z Y
zadzwonimy jednym słowem w alfabecie Y i cyfrę N - długość słowa A. Długość słowa jest oznaczana jako la).
Niech będzie podany alfabet W, W =( B 1 , ..., B Q ). Poprzez B oznaczają słowo w alfabecie W i by S (W)jest zbiorem wszystkich niepustych słów alfabetu W.
Pozwalać S =S(Y) -zbiór wszystkich niepustych słów w alfabecie Y i S"- jakiś podzbiór zbioru S. Niech również zostanie podane mapowanie F, które każde słowo A, A? S(Y), pasuje do słowa
B=F(A), B ? POŁUDNIOWY ZACHÓD) .
Słowo W zadzwonimy kod wiadomości A i przejście od słowa A do jego kodu - kodowanie.
Definicja. Rozważmy zgodność pomiędzy literami alfabetu Y i niektórymi słowami alfabetu W:
A 1
- B
1
,
A 2
- B
2
,
. . .
A R- B R
Ta korespondencja nazywa się schemat i oznaczony przez S. Definiuje kodowanie w następujący sposób: każde słowo z S" (W)=S (W)pasuje do słowa tzw kod słowny A. Słowa B 1 ... B R są nazywane kody elementarne. Ten typ kodowania nazywa się kodowanie alfabetyczne.
Definicja. Niech słowo W wygląda jak
B=B" B"
Potem słowo B" zwany początek Lub przedrostek słowa B., A B" - koniec słowa B. Ponadto puste słowo L i samo słowo B są uważane za początki i końce słów B .
Definicja . Schemat S ma właściwość przedrostka, jeśli na jakikolwiekI I J(1? I , J? r, ja? J B ) słowoI B nie jest przedrostkiem słowa
J. Twierdzenie 1. Jeżeli schemat S
ma właściwość przedrostka, wówczas kodowanie alfabetyczne będzie jeden do jednego. A 1 ,..., A Załóżmy, że alfabet Y =(} (R >1 R ) i zbiór prawdopodobieństw 1 , . . . , ) i zbiór prawdopodobieństw R P A 1 ,..., A Załóżmy, że alfabet Y =(wygląd postaci B 1 , ..., B . Niech dalej będzie podany alfabet W , W =(} (Q >1 Q
). Można wtedy skonstruować całą serię alfabetycznych schematów kodowania S
- B
1
,
. . .
A R- B R
1
posiadający własność jeden do jednego. Dla każdego wzoru możesz wprowadzić średnią długość l Poślubić
![]() , zdefiniowany jako matematyczne oczekiwanie długości kodu elementarnego:
, zdefiniowany jako matematyczne oczekiwanie długości kodu elementarnego:
- długość słów. Dla każdego wzoru możesz wprowadzić średnią długość Długość Poślubić
pokazuje, ile razy zwiększa się średnia długość słowa podczas kodowania według schematu S. Dla każdego wzoru możesz wprowadzić średnią długość l Można to wykazać Dla każdego wzoru możesz wprowadzić średnią długość * osiąga wartość minimalną
Definicja . na pewnym S i jest zdefiniowany jakoKody zdefiniowane przez obwód S za pomocą l Dla każdego wzoru możesz wprowadzić średnią długość * średnia = , są nazywane kody z minimalną redundancją
lub kody Huffmana.
Kody o minimalnej redundancji zapewniają średnio minimalny wzrost długości słów, jeśli są odpowiednio zakodowane. A 1 ,..., A Załóżmy, że alfabet Y =(W naszym przypadku alfabet Y =(
) określa symbole strumienia wejściowego, a alfabet W = (0,1), tj. składa się tylko z zera i jedynki.
Algorytm konstrukcji obwodu S można przedstawić w następujący sposób: Krok 1. B ) słowoWszystkie litery alfabetu wejściowego układamy w malejącej kolejności prawdopodobieństwa. Liczymy wszystkie pasujące słowa
z alfabetu W =(0,1) są puste. Krok 2. Połączenie dwóch symboli ja r-1 Połączenie dwóch symboli IR najmniej prawdopodobny Liczba Pi I najmniej prawdopodobny r-1R do pseudoznaku{Połączenie dwóch symboli ja A" powietrze najmniej prawdopodobny ja+najmniej prawdopodobny I) z prawdopodobieństwem . Dodaj 0 na początku słowa B ja I . Dodaj 0 na początku słowa B ja(B . Dodaj 0 na początku słowa B=0B r-1 . Dodaj 0 na początku słowa B I I . Dodaj 0 na początku słowa B I) i 1 na początek słowa B . Dodaj 0 na początku słowa B I).
=1B Krok 3. Połączenie dwóch symboli ja r-1 Połączenie dwóch symboli IUsunięcie z listy uporządkowanych znaków do pseudoznaku{Połączenie dwóch symboli ja A" , umieść tam pseudosymbol B ) słowo). Wykonaj krok 2, jeśli to konieczne, dodając 1 lub zero do wszystkich słów
, odpowiadające pseudoznakom, aż na liście pozostanie 1 pseudoznak. Przykład: A 1 ,..., A 4 } (R =4 ), ) i zbiór prawdopodobieństw 1 =0.5, ) i zbiór prawdopodobieństw 2 =0.24,Załóżmy, że alfabet Y ma 4 litery =( 3 =0.15,P 4 P

=0,11 . Następnie proces konstruowania diagramu można przedstawić w następujący sposób:
Aby odtworzyć słowa kodujące, musimy podążać za strzałkami od początkowych symboli do końca powstałego drzewa binarnego. A więc dla symbolu z prawdopodobieństwem ) i zbiór prawdopodobieństw
4, otrzymujemy B 4 =101, dla ) i zbiór prawdopodobieństw 3 otrzymujemy B 3 =100, dla ) i zbiór prawdopodobieństw 2 otrzymujemy B 2 = 11, dla ) i zbiór prawdopodobieństw 1 otrzymujemy B 1 =0. Co oznacza diagram:
A 1
- 0,
A 2
- 11
A 3
- 100
A 4
- 101
Ten schemat jest kodem prefiksu, który jest kodem Huffmana. Najczęściej występujący znak w strumieniu A
1
najkrótsze słowo zakodujemy jako 0 i najrzadsze A
4
długie słowo 101.
Dla ciągu 100 znaków, w którym znak A
1
wystąpi 50 razy, symbol A
2
- 24 razy, symbol A
3
- 15 razy i symbol A
4
- 11 razy, ten kod pozwoli ci uzyskać sekwencję 176 bitów ( ![]() ). Te. średnio wydamy 1,76 bitów na symbol strumienia.
). Te. średnio wydamy 1,76 bitów na symbol strumienia.
Dowód twierdzenia, a także fakt, że skonstruowany obwód faktycznie definiuje kod Huffmana, zob.
Jak wynika z powyższego, klasyczny algorytm Huffmana wymaga zapisania w pliku tabeli zgodności pomiędzy zakodowanymi znakami i łańcuchami kodowania.
W praktyce stosuje się jego odmiany. Dlatego w niektórych przypadkach rozsądne jest użycie tabeli stałej lub zbudowanie jej „adaptacyjnie”, tj. podczas archiwizacji/unarchiwizacji. Techniki te oszczędzają nam konieczności dwukrotnego przeglądania obrazu i konieczności przechowywania tabeli wraz z plikiem. Kodowanie stałej tabeli jest używane jako ostatni etap archiwizacji w formacie JPEG i algorytmie CCITT Group 3 omówionym poniżej.
Charakterystyka klasycznego algorytmu Huffmana:
Współczynniki kompresji: 8, 1,5, 1 (najlepszy, średni, najgorszy kurs).
Klasa obrazu: Praktycznie nie dotyczy obrazów w czystej postaci. Zwykle używany jako jeden ze stopni kompresji w bardziej złożonych obwodach.
Symetria: 2 (ponieważ wymaga dwóch przejść przez skompresowaną tablicę danych).
Charakterystyka: Jedyny algorytm, który w najgorszym przypadku nie zwiększa rozmiaru danych źródłowych (poza koniecznością przechowywania tabeli konwersji wraz z plikiem).
Algorytm Huffmana ze stałą tabelą CCITTGrupa 3Podobną modyfikację algorytmu stosuje się przy kompresji obrazów czarno-białych (jeden bit na piksel). Pełna nazwa tego algorytmu to CCITT Group 3. Oznacza to, że algorytm ten został zaproponowany przez trzecią grupę normalizacyjną Komitetu Konsultacyjnego Międzynarodowego Telegrafu i Telefonu. Znajdujące się w nim ciągi kolejnych czarnych i białych kropek zastępujemy liczbą równą ich liczbie. A ta seria z kolei jest skompresowana według Huffmana za pomocą stałego stołu.
Definicja: Nazywa się zbiór kolejnych pikseli obrazu tego samego koloru seria.Nazywa się długość tego zbioru punktów długość serii.
Poniższa tabela zawiera dwa typy kodów:
- Kody zakończenia serii- ustawiany od 0 do 63 w krokach co 1.
- Kody złożone (dodatkowe).- ustawiane od 64 do 2560 w odstępach co 64.
W praktyce, w przypadku gdy obraz jest w przeważającej mierze czarny, przed kompresją odwracamy obraz i zapisujemy informację o tym w nagłówku pliku.
Algorytm kompresji wygląda następująco:
for (nad wszystkimi liniami obrazu) (
Przekształćmy ciąg w zbiór długości odcinków;
dla (w całej serii) (
if(seria biała) (
L= długość biegu;
podczas gdy(L > 2623) ( // 2623=2560+63
L=L-2560;
WriteWhiteCodeFor(2560);
}
jeśli(L > 63) (
L2=MaximumConstCodeLessL(L);
L=L-L2;
WriteWhiteCodeFor(L2);
}
WriteWhiteCodeFor(L);
//To jest zawsze kod wyjścia
}
w przeciwnym razie(
[Kod jest podobny do białej serii,
z tą różnicą, że są rejestrowane
czarne kody]
}
}
// Koniec linii obrazu
}
Ponieważ seria czarno-biała występuje naprzemiennie, kod serii białej i kod serii czarnej będą w rzeczywistości działać naprzemiennie.
W przypadku wyrażeń regularnych dla każdej linii naszego obrazu (wystarczająco długiej, zaczynając od białej kropki) otrzymamy wyjściowy strumień bitów w postaci:
((<Б-2560>)*[<Б-сст.>]<Б-зв.>(<Ч-2560>)*[<Ч-сст.>]<Ч-зв.>) +
[(<Б-2560>)*[<Б-сст.>]<Б-зв.>]
Gdzie ()* - powtórz 0 lub więcej razy, () + .- powtórz 1 lub więcej razy, - włącz 1 lub 0 razy.
Dla przykładu podanego wcześniej: 0, 3, 556, 10... algorytm wygeneruje następujący kod:<Б-0><Ч-3><Б-512><Б-44><Ч-10>lub zgodnie z tabelą 00110101 10 0110010100101101 0000100 (dla wygody wyróżniono różne kody w wątku). Kod ten ma właściwość kodów przedrostkowych i można go łatwo złożyć w sekwencję długości serii. Łatwo policzyć, że dla danego ciągu 569 bitów otrzymaliśmy kod o długości 33 bitów, tj. stopień sprężania wynosi około 17 razy.
Pytanie: Ile razy zwiększy się rozmiar pliku w najgorszym przypadku? Dlaczego? (Odpowiedź podana w charakterystyce algorytmu nie jest kompletna, ponieważ możliwe są większe wartości najgorszego współczynnika kompresji. Znajdź je.)
Należy zwrócić uwagę, że jedyne „złożone” wyrażenie w naszym algorytmie: L2=MaximumAdditionCodeLessL(L) - w praktyce działa to bardzo prosto: L2=(L>>6)*64, gdzie >> jest bitowym przesunięciem L w lewo o 6 bitów (możesz zrobić to samo dla jednej operacji bitowej & - logiczne AND).Ćwiczenia: Biorąc pod uwagę ciąg obrazu zapisany jako długości - 442, 2, 56, 3, 23, 3, 104, 1, 94, 1, 231, 120 bajtów w rozmiarze ((442+2+..+231)/8) . Oblicz stopień kompresji tego ciągu, korzystając z algorytmu CCITT Group 3.
Poniższe tabele zbudowane są przy użyciu klasycznego algorytmu Huffmana (oddzielnie dla długości przebiegów czarno-białych). Prawdopodobieństwa wystąpienia dla określonych długości serii uzyskano poprzez analizę dużej liczby obrazów faksymilowych.Tabela kodów ukończenia:
| Długość
seria |
Biały kod
podciągi |
Kod czarny
podciągi |
Długość
seria |
Biały kod
podciągi |
Kod czarny
podciągi |
|
| 0 | 00110101 | 0000110111 | 32 | 00011011 | 000001101010 | |
| 1 | 00111 | 010 | 33 | 00010010 | 000001101011 | |
| 2 | 0111 | 11 | 34 | 00010011 | 000011010010 | |
| 3 | 1000 | 10 | 35 | 00010100 | 000011010011 | |
| 4 | 1011 | 011 | 36 | 00010101 | 000011010100 | |
| 5 | 1100 | 0011 | 37 | 00010110 | 000011010101 | |
| 6 | 1110 | 0010 | 38 | 00010111 | 000011010110 | |
| 7 | 1111 | 00011 | 39 | 00101000 | 000011010111 | |
| 8 | 10011 | 000101 | 40 | 00101001 | 000001101100 | |
| 9 | 10100 | 000100 | 41 | 00101010 | 000001101101 | |
| 10 | 00111 | 0000100 | 42 | 00101011 | 000011011010 | |
| 11 | 01000 | 0000101 | 43 | 00101100 | 000011011011 | |
| 12 | 001000 | 0000111 | 44 | 00101101 | 000001010100 | |
| 13 | 000011 | 00000100 | 45 | 00000100 | 000001010101 | |
| 14 | 110100 | 00000111 | 46 | 00000101 | 000001010110 | |
| 15 | 110101 | 000011000 | 47 | 00001010 | 000001010111 | |
| 16 | 101010 | 0000010111 | 48 | 00001011 | 000001100100 | |
| 17 | 101011 | 0000011000 | 49 | 01010010 | 000001100101 | |
| 18 | 0100111 | 0000001000 | 50 | 01010011 | 000001010010 | |
| 19 | 0001100 | 00001100111 | 51 | 01010100 | 000001010011 | |
| 20 | 0001000 | 00001101000 | 52 | 01010101 | 000000100100 | |
| 21 | 0010111 | 00001101100 | 53 | 00100100 | 000000110111 | |
| 22 | 0000011 | 00000110111 | 54 | 00100101 | 000000111000 | |
| 23 | 0000100 | 00000101000 | 55 | 01011000 | 000000100111 | |
| 24 | 0101000 | 00000010111 | 56 | 01011001 | 000000101000 | |
| 25 | 0101011 | 00000011000 | 57 | 01011010 | 000001011000 | |
| 26 | 0010011 | 000011001010 | 58 | 01011011 | 000001011001 | |
| 27 | 0100100 | 000011001011 | 59 | 01001010 | 000000101011 | |
| 28 | 0011000 | 000011001100 | 60 | 01001011 | 000000101100 | |
| 29 | 00000010 | 000011001101 | 61 | 00110010 | 000001011010 | |
| 30 | 00000011 | 000001101000 | 62 | 00110011 | 000001100110 | |
| 31 | 00011010 | 000001101001 | 63 | 00110100 | 000001100111 |
Tabela kodów złożonych:
| Długość
seria |
Biały kod
podciągi |
Kod czarny
podciągi |
Długość
seria |
Biały kod
podciągi |
Kod czarny
podciągi |
|
| 64 | 11011 | 0000001111 | 1344 | 011011010 | 0000001010011 | |
| 128 | 10010 | 000011001000 | 1408 | 011011011 | 0000001010100 | |
| 192 | 01011 | 000011001001 | 1472 | 010011000 | 0000001010101 | |
| 256 | 0110111 | 000001011011 | 1536 | 010011001 | 0000001011010 | |
| 320 | 00110110 | 000000110011 | 1600 | 010011010 | 0000001011011 | |
| 384 | 00110111 | 000000110100 | 1664 | 011000 | 0000001100100 | |
| 448 | 01100100 | 000000110101 | 1728 | 010011011 | 0000001100101 | |
| 512 | 01100101 | 0000001101100 | 1792 | 00000001000 | zgodny z białym | |
| 576 | 01101000 | 0000001101101 | 1856 | 00000001100 | - // - | |
| 640 | 01100111 | 0000001001010 | 1920 | 00000001101 | - // - | |
| 704 | 011001100 | 0000001001011 | 1984 | 000000010010 | - // - | |
| 768 | 011001101 | 0000001001100 | 2048 | 000000010011 | - // - | |
| 832 | 011010010 | 0000001001101 | 2112 | 000000010100 | - // - | |
| 896 | 011010011 | 0000001110010 | 2176 | 000000010101 | - // - | |
| 960 | 011010100 | 0000001110011 | 2240 | 000000010110 | - // - | |
| 1024 | 011010101 | 0000001110100 | 2304 | 000000010111 | - // - | |
| 1088 | 011010110 | 0000001110101 | 2368 | 000000011100 | - // - | |
| 1152 | 011010111 | 0000001110110 | 2432 | 000000011101 | - // - | |
| 1216 | 011011000 | 0000001110111 | 2496 | 000000011110 | - // - | |
| 1280 | 011011001 | 0000001010010 | 2560 | 000000011111 | - // - |
Algorytm ten jest zaimplementowany w formacie TIFF.
Charakterystyka algorytmu Grupa CCITT 3
PROFIL Podczas kompresji przy użyciu algorytmu RLE najpierw rejestrowana jest liczba powtórzeń pierwszego znaku, następnie sam pierwszy znak, następnie liczba powtórzeń drugiego znaku itd. W tym przypadku cały zakodowany plik zajmuje 4 bajty: 0 11 00100 2 11 000000 2 011 00100 2 11 000001 2 100 A (kod 192) 100 B (kod 193) Tym samym skompresowaliśmy plik 50 razy, ponieważ znów miał on redundancję - łańcuchy identycznych znaków. Jest to kompresja bezstratna, ponieważ znając algorytm pakowania, można odzyskać oryginalne dane z kodu. Oczywiście takie podejście doprowadzi do zwiększenia (dwukrotnego) ilości danych w przypadku, gdy w pliku nie ma sąsiadujących ze sobą identycznych znaków. Aby poprawić wyniki kodowania RLE nawet w tym najgorszym przypadku, algorytm zmodyfikowano w następujący sposób. Spakowana sekwencja zawiera bajty kontrolne, po każdym bajcie kontrolnym następuje jeden lub więcej bajtów danych. Jeśli najbardziej znaczący bit bajtu kontrolnego wynosi 1, wówczas bajt danych następujący po bajcie kontrolnym podczas rozpakowywania musi zostać powtórzony tyle razy, ile jest zapisany w pozostałych 7 bitach bajtu kontrolnego. Jeśli najbardziej znaczący bit bajtu kontrolnego ma wartość 0, wówczas kilka następnych bajtów danych należy pobrać bez zmian. Ile dokładnie jest zapisane w pozostałych 7 bitach bajtu kontrolnego. Na przykład bajt kontrolny 10000 11 1 2 oznacza, że kolejny bajt należy powtórzyć 7 razy, a bajt kontrolny 00000100 2 oznacza, że kolejne 4 bajty należy przyjąć bez zmian. Zatem ciąg wynosi 1000 11 11 2 11 000000 2 00000010 2 11 000001 2 11 000010 2 powtórzenie 15 A (kod 192) 2 B (kod 193) B (kod 194) jest rozpakowane na 17 znaków: AAAAAAAAAAAAAAAABV. Algorytm RLE został z powodzeniem zastosowany do kompresji rysunków, w których duże obszary są wypełnione tym samym kolorem i niektórymi danymi dźwiękowymi. Obecnie stosuje się bardziej zaawansowane, ale bardziej złożone metody. Przyjrzymy się jednemu z nich (kodowanie Huffmana) poniżej. Algorytm RLE wykorzystywany jest np. na jednym z etapów kodowania zdjęć do formatu JPEG. Kompresja RLE dostępna jest także w formacie BMP (dla obrazów z paletą 16 lub 256 kolorów). Najlepszym sposobem zrozumieć zasadę działania algorytmu – przećwiczyć jego użycie. Ze strony autora (http://kpolyakov.narod.ru/prog/compress.htm) można pobrać darmowy program symulacyjny przeznaczony do badania algorytmu RLE: Po lewej stronie programu znajduje się edytor tekstu okno. Po kliknięciu przycisku wprowadzony tekst jest kompresowany przy użyciu algorytmu RLE, skompresowane dane są wyświetlane w postaci kodów szesnastkowych po prawej stronie okna. Okno po prawej stronie jest jednocześnie edytorem, dzięki czemu po kliknięciu na przycisk można dokonać zmiany kodów oraz wykonać operację odwrotną (rozpakowanie, dekompresja). Przyciski znajdujące się w górnej części okna pozwalają na kompresję i przywracanie plików na dysku. Trzeba tylko wziąć pod uwagę, że program wykorzystuje własny format przechowywania danych. 6 grudnia 2012 / INFORMATION SCIENCE Pytania testowe 1) Oszacuj maksymalny osiągalny stopień kompresji wykorzystując rozważaną wersję algorytmu RLE. W jakim przypadku uda się to osiągnąć? 2) Oszacuj współczynnik kompresji w najgorszym przypadku, korzystając z algorytmu RLE. Opisz ten najgorszy scenariusz. 3) Wymyśl trzy sekwencje, których nie można skompresować za pomocą algorytmu RLE. 4) Konstruuj sekwencje skompresowane przez algorytm RLE dokładnie 2 razy, 4 razy, 5 razy. Praktyka 1) Używając algorytmu RLE, zakoduj ciąg znaków BBBBBBACCCABBBBBB Wynik zapisz w postaci kodów szesnastkowych (każdy znak jest kodowany jako bajt, który jest reprezentowany przez dwie cyfry szesnastkowe). Sprawdź wynik za pomocą programu RLE.
2) Odkoduj sekwencję spakowaną algorytmem RLE (podawane są kody szesnastkowe): 01 4D 8E 41 01 4D 8E 41 16. Aby zidentyfikować znaki po ich kodach szesnastkowych, użyj tabeli ASCII. Określ liczbę bajtów w oryginalnej i zdekompresowanej sekwencji i oblicz współczynnik kompresji. Sprawdź wynik za pomocą programu RLE. Zaproponuj dwie metody weryfikacji. 3) Za pomocą programu RLE zastosuj kompresję RLE do następujących 1 plików i znajdź współczynnik kompresji dla każdego z nich. grad_vert.bmp grad_horz.bmp grad_diag.jpg Wyjaśnij uzyskane wyniki: dlaczego dla dwóch obrazów w formacie BMP o tej samej wielkości współczynniki kompresji przy użyciu algorytmu RLE są tak różne; Dlaczego nie mogę kompresować zdjęć zapisanych w formacie JPEG? Kody prefiksowe Pomyśl o kodzie Morse'a, który wykorzystuje nierówny kod w celu zmniejszenia długości wiadomości - często występujące litery (A, E, M, H, T) są kodowane w krótkich sekwencjach, a rzadko występujące są kodowane w dłuższych sekwencjach. Taki kod można przedstawić w postaci struktury zwanej drzewem: Korzeń Pokazuje to niekompletne drzewo alfabetu Morse'a, zbudowane tylko dla znaków, których kody składają się z jednego i dwóch znaków (kropki i myślnika). Drzewo składa się z węzłów (czarna kropka i okręgi z symbolami alfabetu) oraz łączących je skierowanych krawędzi, strzałki wskazują kierunek ruchu. Górny węzeł (który nie zawiera żadnych strzałek) nazywany jest „korzeniem” drzewa. Z korzenia i ze wszystkich węzłów pośrednich (z wyjątkiem węzłów końcowych - „liście”) wychodzą dwie strzałki, lewa jest oznaczona kropką, a prawa kreską. Aby znaleźć kod symbolu, należy podążać za strzałkami od „korzenia” drzewa do pożądanego „liścia”, zapisując etykiety strzałek, którymi podążamy. W drzewie nie ma cykli (ścieżek zamkniętych), więc kod dla każdego 1. Te i inne pliki wykorzystane w zadaniach warsztatowych znajdują się na dysku dodatkowym do tego numeru czasopisma. charakter jest określony w wyjątkowy sposób. Korzystając z tego drzewa, możesz zbudować następujące kody: E I A – T – N – M – – Jest to kod nieparzysty, w którym znaki mają kody o różnej długości. W takim przypadku zawsze pojawia się problem podziału sekwencji na osobne słowa kodowe. W alfabecie Morse'a rozwiązuje się to za pomocą znaku separatora - pauzy. Nie musisz jednak wprowadzać dodatkowego znaku, jeśli spełniony jest warunek Fano: żadne ze słów kodowych nie jest początkiem innego słowa kodowego. Dzięki temu można jednoznacznie rozszyfrować wiadomość w czasie rzeczywistym, w miarę odbierania kolejnych znaków. Kod prefiksowy to kod, w którym żadne słowo kodowe nie jest początkiem innego słowa kodowego (warunek Fano). Robert Fano (ur. 1917) (nytimes.com) Claude Shannon (1916–2001) Aby wykorzystać tę koncepcję w komputerowym przetwarzaniu danych, konieczne było opracowanie algorytmu konstruowania kodu przedrostkowego. Problem ten po raz pierwszy rozwiązali niezależnie od siebie amerykańscy matematycy i inżynierowie Claude Shannon (w 1948 r.) i Robert Fano (w 1949 r.). Zastosowano redundancję komunikatu, która polega na tym, że znaki w tekście mają różną częstotliwość występowania. W takim przypadku należy dwukrotnie odczytać dane z pliku źródłowego: w pierwszym przebiegu określana jest częstotliwość występowania każdego znaku, następnie budowany jest kod uwzględniający te dane, a w drugim przebiegu tekst znaki są zastępowane ich kodami. Algorytm kodowania zaproponowany przez Shannona i Fano nazwano kodem Shannona-Fano. Przykład 3. Niech tekst składa się tylko z liter O, E, N, T i spacji. Wiadomo, ile razy pojawiły się w tekście: spacja – 179, O – 89, E – 72, N – 53 i T – 50 razy. Zgodnie z metodą Shannona-Fano znaki dzielimy na dwie grupy tak, aby łączna liczba znaków z pierwszej grupy występujących w tekście była w przybliżeniu równa całkowitej liczbie znaków z drugiej grupy. W naszym przypadku najlepsza opcja- to połączenie spacji i litery T w pierwszą grupę (suma 179+50 = 229), a pozostałych znaków w drugą (suma 89+72+53 = 214). Znaki z pierwszej grupy będą miały kody zaczynające się od 0, a pozostałe od 1. W pierwszej grupie są tylko dwa znaki, jeden z nich, np. spacja, będzie miał drugą cyfrę kodu 0 (i pełny kod 00), a drugi będzie miał 1 (kod literowy T - 01). 7 grudnia 2012 / INFORMATYKA
- W kontakcie z 0
- Google+ 0
- OK 0
- Facebook 0






